网站建设分金手指排名四北京网站优化外包
文章目录
- 关于PASCAL VOC数据集
- 目录结构
- ①创建VOC数据集的几个相关目录
- XML文件的形式
- ②读取dcm文件与xml文件的配对关系
- ③创建VOC格式数据集
- ④创建训练、验证集
本文所用代码见文末Github链接。
关于PASCAL VOC数据集
pascal voc数据集是关于计算机视觉,业内广泛使用的一套具有标准格式的数据集。包括了图像分类、目标检测、语义分割等任务。
许多深度学习框架如Pytorch中写好的一些模型都是可以默认读取这种Pascal VOC格式的数据集的,这样就方便我们对数据集进行各种处理、实验。
Pascal VOC2012 train/val数据集官方下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
更多信息见:官网。下载更多内容可参考:镜像站(可下载测试集)。
目录结构
它的格式信息(目录结构)如下

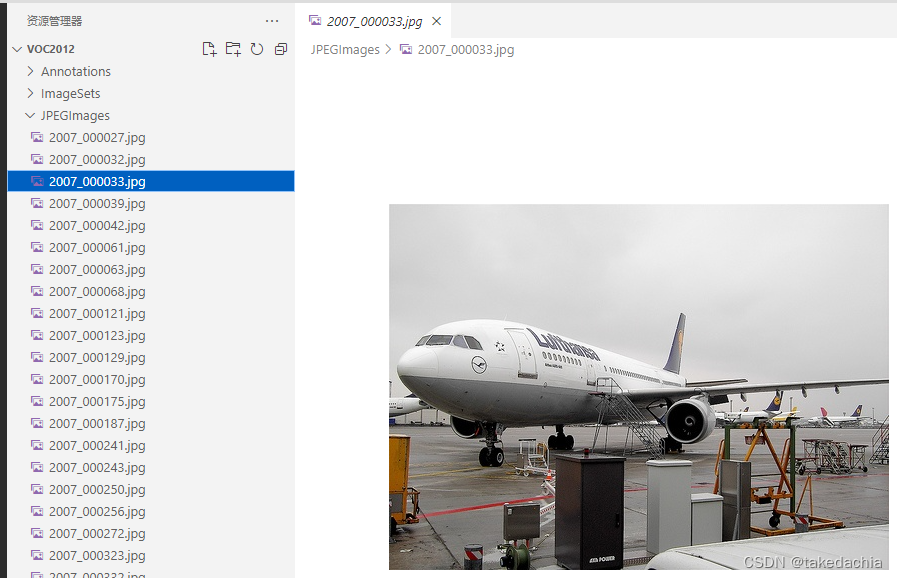
我们目标检测主要使用上面的Annotation、JPEGImages、ImageSets/Main文件夹。
ImageSets/Main文件夹下train.txt包含了被纳入训练集的图片,里面是JPEGImages文件夹下图片的文件名。
val.txt则是验证集的图片文件名集合。
trainval.txt是以上两者的合集。
展示:
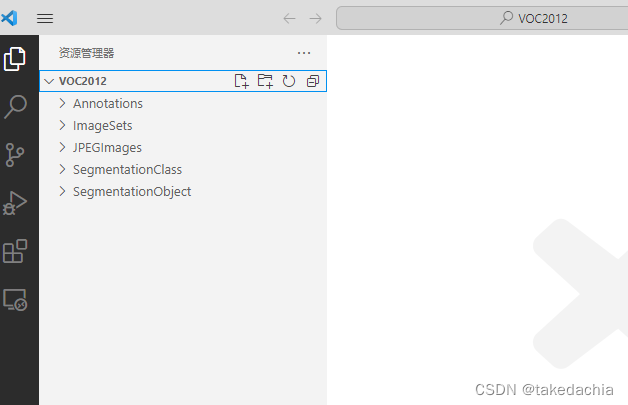
图片
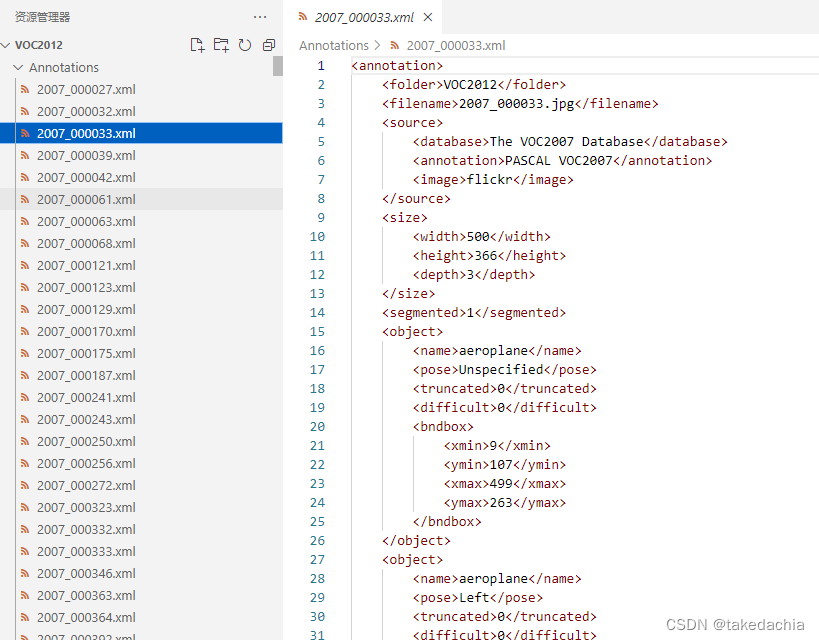
标注文件。
可以见到标注文件xml的格式和Lung-PET-CT-Dx数据集中的标注文件格式基本是一样的。
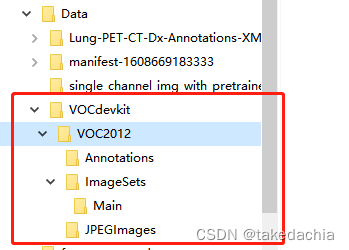
①创建VOC数据集的几个相关目录
与目标检测相关的只有:
VOCdevkit/VOC2012/Annotation (存放xml标注文件)
VOCdevkit/VOC2012/ImageSets/Main (存放train.txt、val.txt)
VOCdevkit/VOC2012/JPEGImages (存放图像文件)
在上一节我们已经进行了数据整理,并建立了简易的Dataset数据集对象。
我们已创建了 [dcm图片集] 和 [xml标注集] 的一个对应关系,我们试者重新创建一个Pascal VOC格式的数据集,顺便可以给数据集瘦瘦身。
我们先在项目目录下创建如下目录:
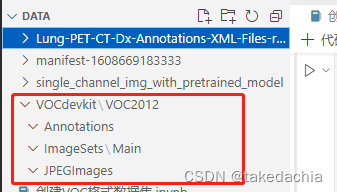
Windows资源管理器界面:
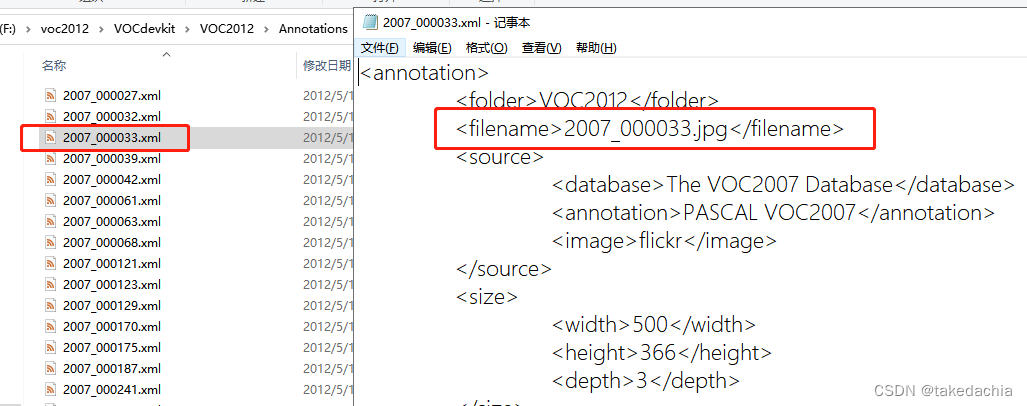
XML文件的形式
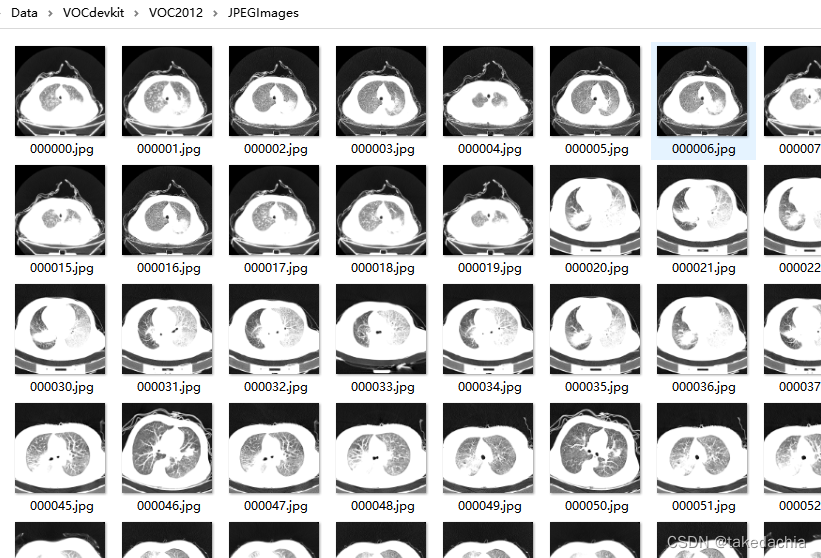
我们知道VOC数据集中,所有的图片文件存在了JPEGImages文件夹,且有自己的文件名。
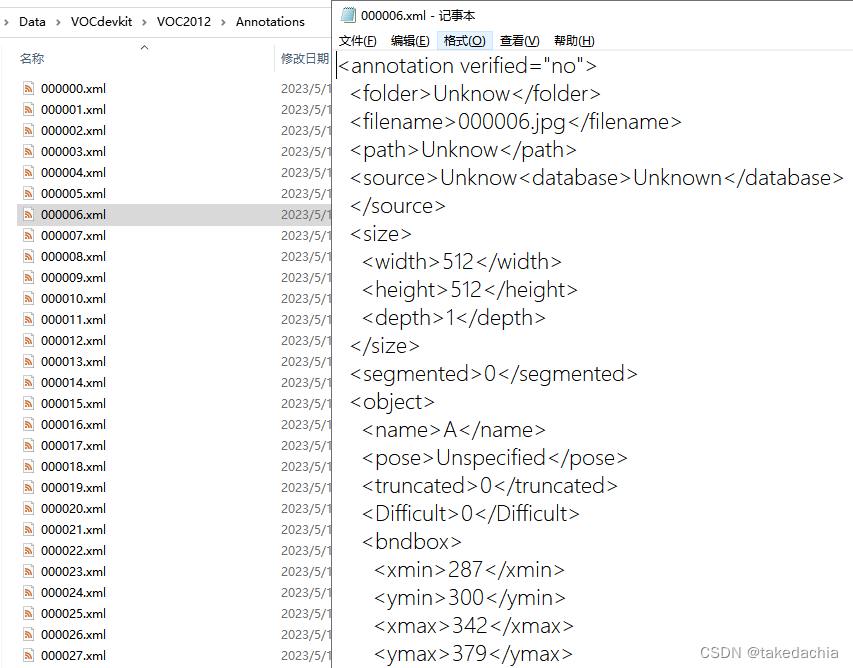
在Annotation文件夹下,xml标注文件的文件名对应了图片的文件名,且xml文件中的 [filename] 项对应了图片的文件名+扩展名。
我们的目标是让Lung-PET-CT-Dx也改成这样的形式。
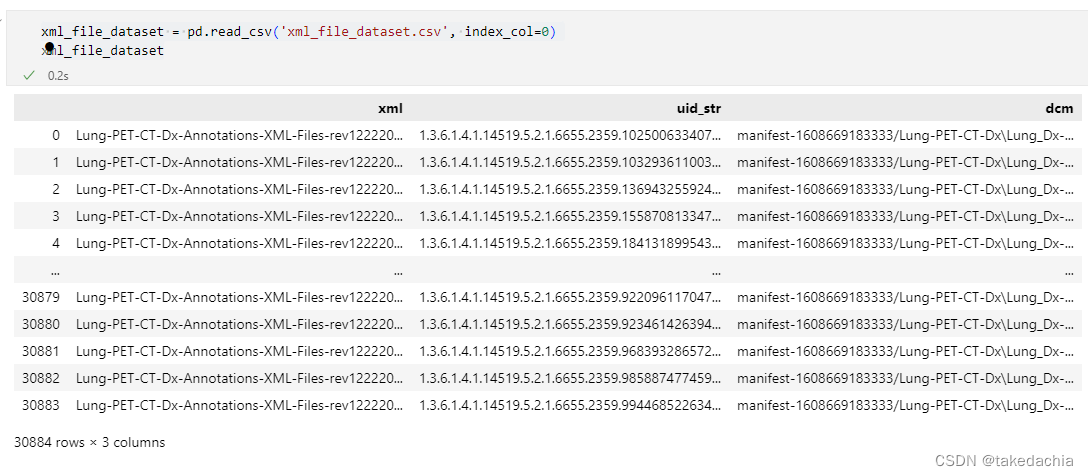
②读取dcm文件与xml文件的配对关系
在上一篇文章已经创建了这一配对表,直接读取csv文件。
import pydicom
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
import pandas as pd
import numpy as np
import cv2 as cv
from PIL import Image
import xml.etree.ElementTree as ETxml_file_dataset = pd.read_csv('xml_file_dataset.csv', index_col=0)
xml_file_dataset
我们添加新的一列,赋予它们新的名字:编号从 000000~03883。
xml_file_dataset['filename'] = xml_file_dataset.index.values
xml_file_dataset['filename'] = xml_file_dataset['filename'].astype(str)
xml_file_dataset['filename'] = xml_file_dataset['filename'].str.zfill(6)
xml_file_dataset
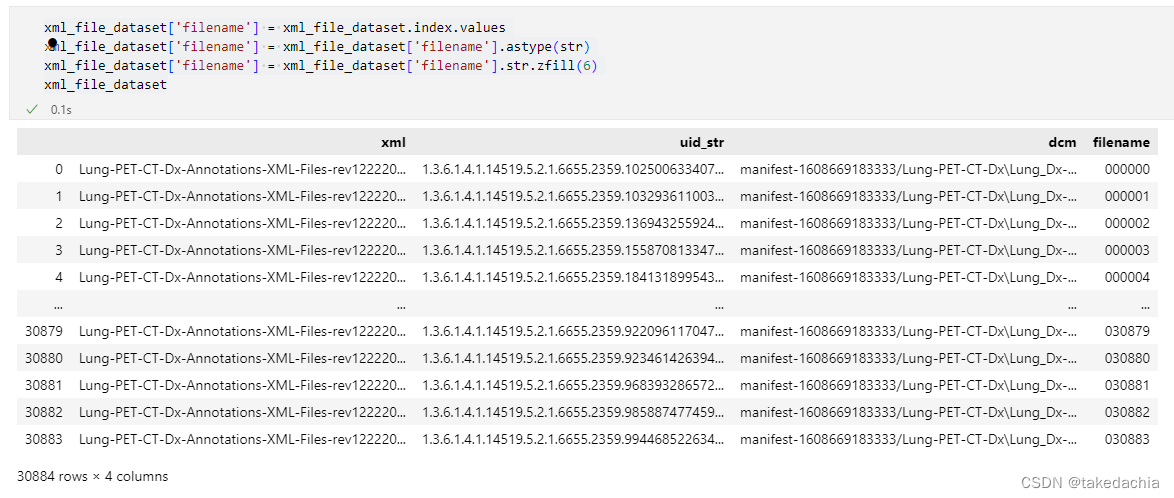
这列filename就是新的文件名。
③创建VOC格式数据集
思路:
- 将xml列的xml文件中的 [filename] 标签写入“filename列对应名称.jpg”(如:000000.jpg),并命名为“ filename列对应名称.xml” (如:000000.xml)保存到 VOCdevkit/VOC2012/Annotations 文件夹下。
- 将dcm列的dcm文件另存为 “filename列对应名称.jpg”(如:000000.jpg),存到 VOCdevkit/VOC2012/JPEGImages文件夹下。
xml_list = xml_file_dataset['xml'].values
dcm_list = xml_file_dataset['dcm'].values
filename_list = xml_file_dataset['filename'].values# 将xml文件中的[filename]标签写入“filename列对应名称.jpg”(如:000000.jpg),并命名为“ filename列对应名称.xml” (如:000000.xml)保存到 VOCdevkit/VOC2012/Annotations 文件夹下。
def to_switch_xml(xml, filename):tree = ET.parse(xml)root = tree.getroot()sub1 = root.find('filename')sub1.text = filename + '.jpg'tree.write('./VOCdevkit/VOC2012/Annotations/{}.xml'.format(filename))# 将dcm文件另存为 “filename列对应名称.jpg”(如:000000.jpg),存到 VOCdevkit/VOC2012/JPEGImages文件夹下。
def to_switch_dcm(dcm, filename):img_open=pydicom.read_file(dcm)img_array=img_open.pixel_array# 将PETCT的三通道格式转成单通道格式if len(img_array.shape) == 3:img_array = cv.cvtColor(img_array, cv.COLOR_BGR2GRAY)img_array = np.array(img_array, dtype=np.float32)img = Image.fromarray(img_array)img = img.convert('L')# quality参数: 保存图像的质量,值的范围从1(最差)到95(最佳)。 默认值为75,使用中应尽量避免高于95的值; 100会禁用部分JPEG压缩算法,并导致大文件图像质量几乎没有任何增益。img.save('./VOCdevkit/VOC2012/JPEGImages/{}.jpg'.format(filename), quality=95)img.close()
# 在SSD上预计需要跑2分钟
for xml, filename in tqdm(zip(xml_list, filename_list), total=len(xml_list)):to_switch_xml(xml, filename)# 在SSD上预计需要跑10分钟
for dcm, filename in tqdm(zip(dcm_list, filename_list), total=len(dcm_list)):to_switch_dcm(dcm, filename)
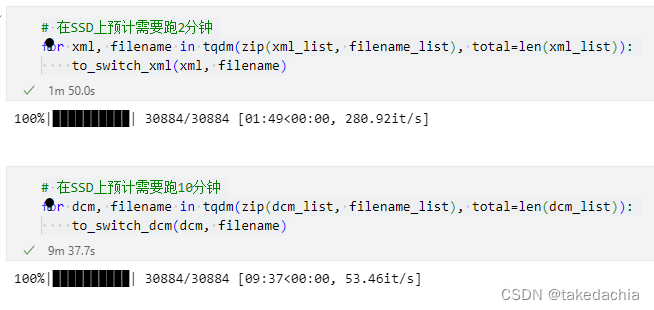
xml文件创建成功:
图像文件创建成功:
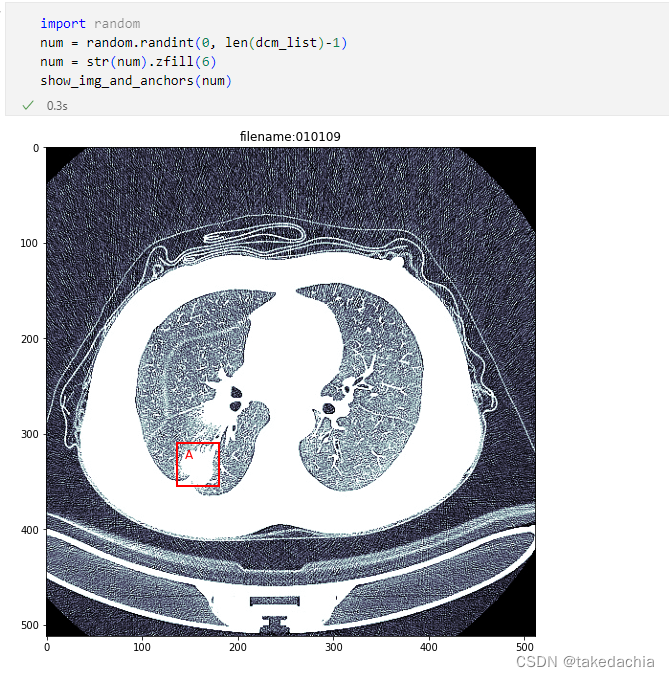
测试一下。
(测试的详细代码见文末的Github地址)
④创建训练、验证集
ImageSets/Main文件夹下创建 train.txt、val.txt
import os
import randomrandom.seed(0) # 设置随机种子,保证随机结果可复现files_path = "./VOCdevkit/VOC2012/Annotations"
assert os.path.exists(files_path), "path: '{}' does not exist.".format(files_path)val_rate = 0.3 # 设置多少归为验证集files_name = sorted([file.split(".")[0] for file in os.listdir(files_path)])
files_num = len(files_name)
val_index = random.sample(range(0, files_num), k=int(files_num*val_rate))
train_files = []
val_files = []
for index, file_name in enumerate(files_name):if index in val_index:val_files.append(file_name)else:train_files.append(file_name)try:train_f = open("./VOCdevkit/VOC2012/ImageSets/Main/train.txt", "x")eval_f = open("./VOCdevkit/VOC2012/ImageSets/Main/val.txt", "x")train_f.write("\n".join(train_files))eval_f.write("\n".join(val_files))
except FileExistsError as e:print(e)exit(1)
创建成功!
本文所用代码: 我的Github