网站建设网页设计小江桔子seo网

赛题名称:Benetech - Making Graphs Accessible
赛题链接:https://www.kaggle.com/competitions/benetech-making-graphs-accessible
赛题背景
数以百万计的学生有学习、身体或视力障碍,导致人们无法阅读传统印刷品。这些学生无法访问科学、技术、工程和数学 (STEM) 领域的大多数教育材料。存在使书面文字易于访问的技术。但是,对于图形等教育视觉对象执行此操作仍然很复杂且需要大量资源。因此,只有一小部分教育材料可供具有这种学习差异的学习者使用——除非机器学习可以帮助弥合这一差距。
赛题方向
计算机视觉、图文描述
赛题任务
本次竞赛的目标是提取由STEM教科书中常见的四种图表表示的数据。参赛者将开发一个在图形数据集上训练的自动解决方案。
参赛者的工作将有助于数百万有学习差异或残疾的学生能够阅读图表。
评价指标
单个图形的数据系列包含两个用于评估的实例:沿 x 轴的一系列值和沿 y 轴的相应值系列。每个数据系列可以是数字类型,也可以是分类类型,具体取决于图表类型。
图形约定参阅:https://www.kaggle.com/competitions/benetech-making-graphs-accessible/overview/graph-conventions
预测数据系列通过两个指标的组合进行评估:分类(即字符串)数据类型的 Levenshtein 距离和数值数据类型的 RMSE,图表类型和序列中的值数具有初始完全匹配标准。这些距离中的每一个都通过 S 形变换重新缩放并映射到公共相似性尺度,其最佳值为 1:
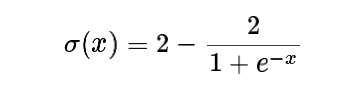
-
提交文件
提交文件中的每一行都应该包含测试集中图形的一个轴的预测序列。例如,abc123 x将给出图abc123中x轴的预测。系列的值应该在单个字符串内,并由;分隔。参赛者还必须为轴所属的图表提供适当的类型。
该文件应包含标头并具有以下格式:
id,data_series,chart_type
abc123_x,2;3;4;5,horizontal_bar
abc123_y,a;b;c;d,horizontal_bar
数据描述
本次比赛的数据集包括约65,000个综合注释的科学图形,分为垂直条形图、水平条形图、点图、折线图和散点图五种。
文件和字段说明:
-
train/annotations/ 描述图形的JSON图像注释集合
-
train/images/ JPG格式的数字集合,用作训练数据
-
test/images/ 收集用作测试数据的数据
-
sample_submission.csv 格式正确的提交文件
时间安排
-
2023.3.21 - 开始报名
-
2023.6.5 - 报名截止
-
2023.6.5 - 团队报名截止
-
2023.6.12 - 最终提交截止
赛题奖金
-
第一名 - 15,000 美元
-
第二名 - 10,000 美元
-
第三名 - 8,000 美元
-
第四名 - 7,000 美元
-
第五名 - 5,000 美元
-
第六名 - 5,000 美元
金牌方案
第一名
https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418786
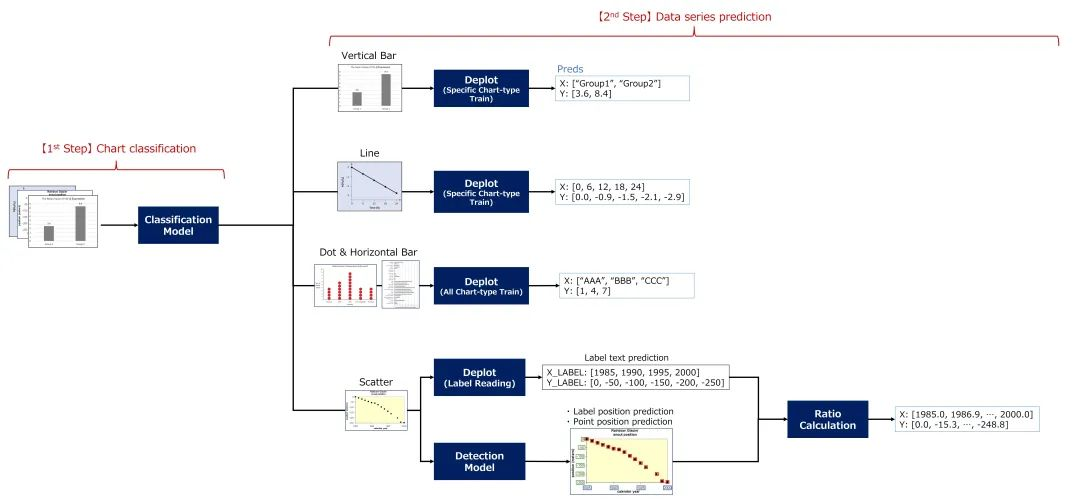
我的解决方案由两步组成:第一步使用分类模型对图表类型进行分类,第二步对数据系列进行推断。
在数据系列推断阶段,条形图、折线图和散点图通过为每个图表类型单独训练的Deplot进行端到端预测,而散点图则通过基于目标检测的方法预测。
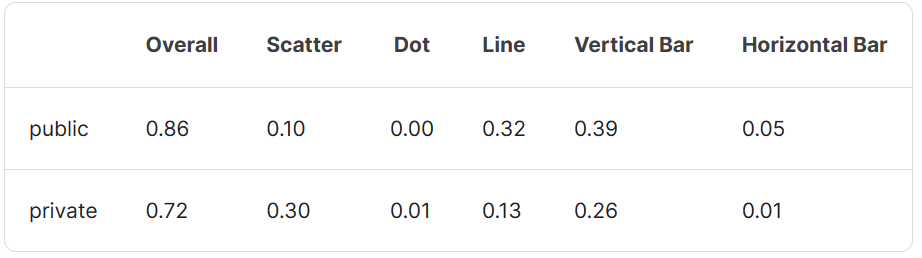
最终得分如下:
数据集
1.比赛数据集(comp_extracted_dataset/comp_generated_dataset)
-
使用了提取数据集(comp_extracted_dataset)和生成数据集(comp_generated_dataset)。
-
对生成的数据,通过简单检查去除了注释中存在噪声的数据(约100张图片)。
2.ICDAR数据集(ICDAR_dataset/ICDAR_manualannot_dataset)
-
我使用了提供了注释的数据1406件(ICDAR_dataset)和没有提供注释的数据1903件(ICDAR_manualannot_dataset)。
-
对于提供了注释的数据,我视觉重新检查了注释内容,并手动修正了所有没有遵循比赛注释规则(例如%表示法)或包含噪声的数据。
-
对于没有提供注释的数据,我首先视觉检查了所有数据的外观,选择了可以在本次比赛中使用的数据。接下来,我使用Deplot模型推断并赋予伪标签,再次视觉检查所有结果,并手动修正所有不正确的注释。
3.生成的合成数据集(synthetic_dataset)
-
在检查了比赛数据集中的图像后,确定comp_generated_dataset本身的变化不足以实现鲁棒性,因此我又自行生成了约65k个合成数据。
- 我主要生成了comp_generated_dataset没有的特征的合成数据。
-
直方图
-
标签包含换行
-
带误差棒的条形图
-
包含数据系列中没有的x标签的折线图
-
第二名
https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418430
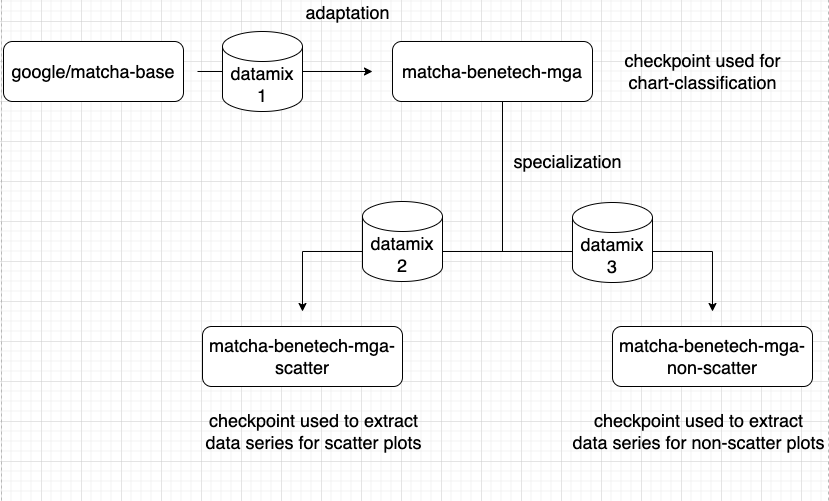
我的解决方案完全基于从google/matcha-base骨干微调得到的图像文本模型。如下图所示,训练流程包含两个阶段。在第一阶段,我利用大量合成图表来适配当前任务的骨干模型。在第二阶段,我使用过采样的提取/非生成图表来使流水线专门适应真实世界的图表。在这个阶段,我为散点图和非散点图创建了独立的模型,主要是为了缓解预测散点数据点的难度。
第一阶段使用合成数据对骨干模型进行预训练,第二阶段使用真实数据进行微调,最终获得一个适合真实世界图表的图像文本模型。两阶段训练使模型既能从合成数据中获取概括能力,也能从真实数据中获取针对真实图表的拟合能力。独立处理散点图也是提高性能的一个关键决策。
1.模型
所有模型共享相同的架构(图像到文本的transformer)和输入输出模式。模型输入直接是图表图像本身,没有任何提示。输出文本遵循以下模板:
{chart_type} {n_x} | {n_y} {x0} | {x1} | {x2} | … | {xn} {y0} | {y1} | {y2} | … | {ym}
一些细节:
-
数值被转换为科学计数法,使用 val = "{:.2e}".format(float(val))。
-
增加了直方图作为额外的图表类型,在后处理中将其转换为垂直条形图。
2.数据
合成数据集
我花费了大部分时间来创建合成数据集。合成图表中的基础数据,我使用了:
-
维基表格数据,即来自维基百科的表格(25%)
-
合成XY数据(75%)
合成数据集包括:
-
10万个横向条形图
-
10万个垂直条形图+直方图
-
10万个散点图
-
20万个折线图
-
20万个散点图
合成数据集 - Bartley
-
从@brendanartley分享的合成数据集中随机选择了2.5万个数据点:https://www.kaggle.com/datasets/brendanartley/benetech-extra-generated-data
-
伪标记(Pseudo Labelling):我从维基共享资源(wikimedia commons)截取了大约700张图片。我使用了伪标记,并进行了手动修正,以生成注释。
-
ICDAR数据集:我使用了约1100张来自ICDAR的图片,只使用那些有1个XY系列的(250条水平条形图 + 450条垂直条形图 + 250条折线图 + 150个散点图)。我还进行了后处理,以确保注释与比赛图表惯例匹配(例如处理百分比、插值线图数据以匹配刻度标签等)。
3.数据混合(Datamix)
-
数据混合1:用于域适应
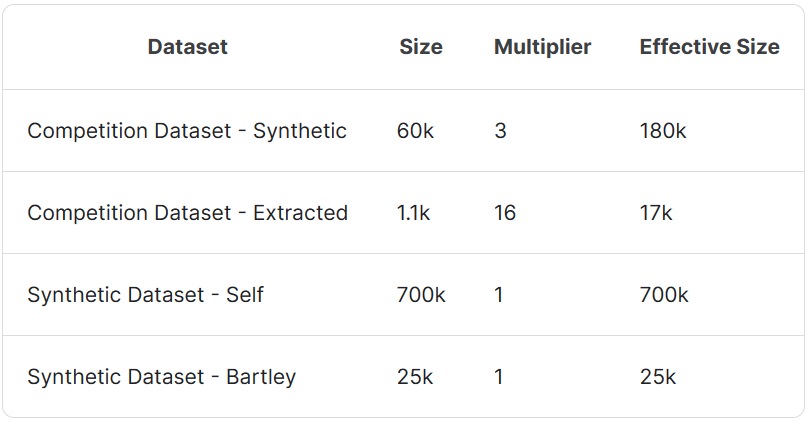
-
数据混合2:散点图专用

-
数据混合3:非散点图专用
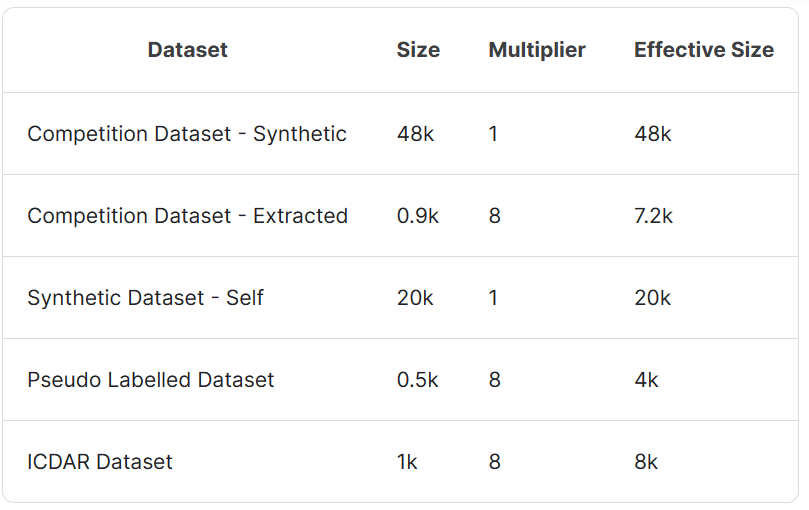
4.训练
训练的主要超参数是max_patches和max_length。我在不同的训练阶段使用了以下设置:
第一阶段训练
-
max_patches: 2048
-
max length: 1024
-
lr: 5e-5
-
batch size: 2
-
gradient accumulation: 16
第二阶段训练 - 非散点图
-
max_patches: 4096
-
max length: 512
-
lr: 2e-5
-
batch size: 4
-
gradient accumulation: 2
第二阶段训练 - 散点图
-
max_patches: 3072
-
max length: 1024
-
lr: 2e-5
-
batch size: 8
-
gradient accumulation: 1
-
AWP
作为小细节,我在训练过程中使用了模型权重的指数移动平均(EMA)、梯度截断和线性热身的余弦调度器。
5.数据增强
由于我重复使用了多次提取的图像,所以我决定包括以下增强:
transforms = A.Compose([A.OneOf([A.RandomToneCurve(scale=0.3),A.RandomBrightnessContrast(brightness_limit=(-0.1, 0.2),contrast_limit=(-0.4, 0.5),brightness_by_max=True,),A.HueSaturationValue(hue_shift_limit=(-20, 20),sat_shift_limit=(-30, 30),val_shift_limit=(-20, 20))],p=0.5,),A.OneOf([A.MotionBlur(blur_limit=3),A.MedianBlur(blur_limit=3),A.GaussianBlur(blur_limit=3),A.GaussNoise(var_limit=(3.0, 9.0)),],p=0.5,),A.Downscale(always_apply=False, p=0.1, scale_min=0.90, scale_max=0.99),],p=0.5,)
第三名
https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418420
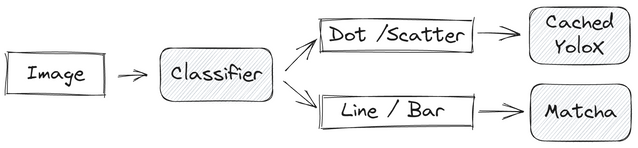
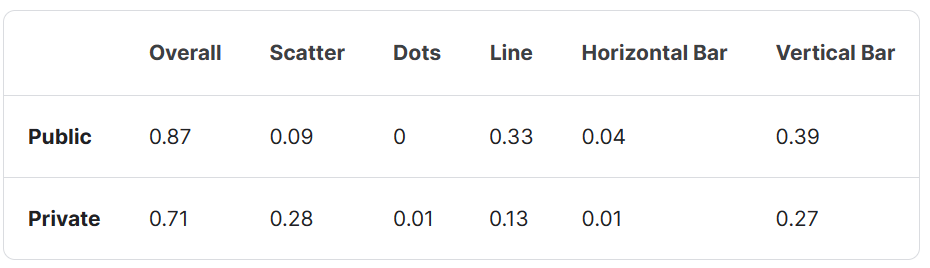
我们的解决方案是一个两步流水线,第一步是一个简单的分类任务,第二步针对不同的图表类型解决任务。对于散点图,我们使用了检测方法。对于折线图和条形图,Matcha的表现非常强劲。下面是我们的LB分数:
验证与见解
-
第一步 - 分类:在这一步中没有太多花哨的东西,我们在(benetech + theo + crodoc)生成的数据上训练模型。
主要参数:
-
2个周期对88k张图像进行训练。
-
学习率3e-4或5e-4(混合使用2个学习率,我们也用了2个随机种子))。
-
使用Mixup和一些颜色增强。
-
图像尺寸为256x384。
-
NfNet-l2并添加0.2的dropout。
-
第二步.a - 散点图
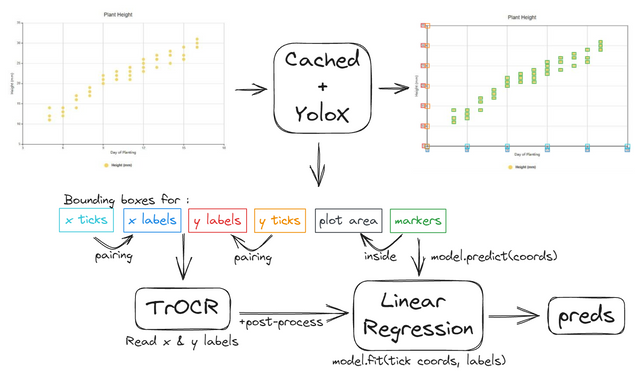
对于散点图,我们依赖于YoloX来检测所有标记。Cached被用来处理其他有用的元素。如果所有点都被正确检测,推断目标并不复杂:检测刻度线和标签,读取标签值,并插值。
更多细节:
-
集成YoloX-m和YoloX-l,使用NMS,有助于减少假阴性。
-
模型在散点图和点图的benetech生成数据上训练了10个epoch,以及我生成并伪标注的一堆绘图。
-
内部验证集0.67,公开LB约0.09,私有LB 0.29 - 性能下降几乎完全来自重叠/难以检测的标记。
-
大量后处理来使流水线更具鲁棒性,抵御OCR错误和检测错误。
-
我们最初使用Yolo-v7,但由于第一次规则更改,不得不切换到YoloX。我们花了一个星期的时间用YoloX匹配Yolo-v7的性能。
-
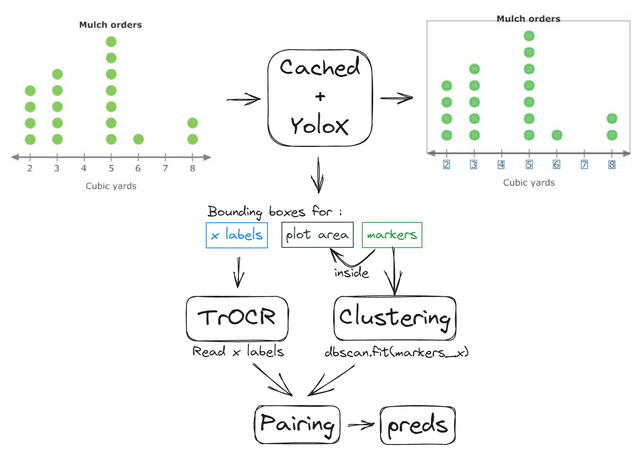
第二步.b - 点图
点图流水线类似于散点图,但更简单一些。我们检测点并进行聚类,然后将它们映射到检测到的x轴标签。没有分配簇的标签被赋值为目标0,其他的给定检测到的点数。由于点数对检测错误不太稳健,我们改为使用最高点的高度并进行插值。
-
第二步.c - 条形图和折线图
Matcha在这里非常强大。我们使用了matcha-base,并将is_vqa设置为False,以避免将文本作为输入给模型。
我们训练Matcha为一张图像预测图表类型、x轴和y轴。ground truth看起来与@nbroad用于他的donut方法相同(除了我们删除了提示符号)。我们尝试了其他方法,但这个效果最好:
x_str = X_START + ";".join(list(map(str, xs))) + X_END
y_str = Y_START + ";".join(list(map(str, ys))) + Y_END
ground_truth = '<' + chart_type + '>' + x_str + y_str
我们获得的最有价值的提升是使用matplotlib生成额外的图表。我们重用了训练集的数据值和文本来生成刻度线和值,使用不同的样式/模式/字体/颜色来增加多样性。生成额外图像的代码有大约1000行,基本上覆盖了模型在“提取”数据集上验证时的大多数失败情况(例如负值、线条边缘、缺失的条形、多行文本、文本旋转等)。
第四名: https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418604
第五名: https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418477
第六名: https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418466
第七名: https://www.kaggle.com/competitions/benetech-making-graphs-accessible/discussion/418510
关注下方【学姐带你玩AI】🚀🚀🚀
回复“图表识别”获取完整金牌方案baseline代码
码字不易,欢迎大家点赞评论收藏!