微网站模板开发百度推广的广告真实可信吗
流程
读取数据
original_data = pd.read_csv(“Penguins.csv”)
original_data.head()
评估和清理数据
cleaned_data = original_data.copy() #备份
结构
original_data.sample(5)
数据符合“每个变量为一列,每个观察值为一行,每种类型的观察单位为一个表格”,才不存在结构性问题。
内容
更改数据类型
cleaned_data[“sex”]=cleaned_data[“sex”].astype(“category”)——把分类变量从object变成category
空缺值
cleaned_data.info()——了解大概哪列缺,缺多少
cleaned_data[cleaned_data[“culmen_length_mm”].isnull()]——提取缺失值对应的行
cleaned_data.drop(3, inplace=True)——缺失得太厉害,没有价值的行直接删除。
缺失性别变量的观察值具备其它数据,仍然可以为分析提供价值。由于Pandas以及Matplotlib、Seaborn会自动忽略缺失值,可以保留这些行。
重复值
**根据数据变量的含义以及内容来看,允许变量重复,**我们不需要对此数据检查是否存在重复值。
什么是不能重复的?比如学号。
不一致数据
重点检查分类变量。
cleaned_data[“sex”].value_counts()
sex列里存在一个英文句号值,并不代表任何有效性别,我们应当把该值替换为NaN空值。
cleaned_data[‘sex’] = cleaned_data[‘sex’].replace(“.”, np.nan)
脱离实际的数据
cleaned_data.describe()
从以上统计信息来看,cleaned_house_price里不存在脱离现实意义的数值。
数据可视化探索
sns.set_palette(“pastel”) #设置图表色盘为"pastel"
单个分类变量——饼图
species_count = cleaned_data[“species”].value_counts() #统计类别对应的个数
plt.pie(species_count,labels=species_count.index,autopct=“%.1f%%”) #标签就用统计生成的标签索引
可以看出比例分布。
两两分类变量——countplot+hue颜色分类
sns.countplot(data=cleaned_data, x=“island”, hue=“species”)
可以显示不同岛上的企鹅种类数量。
数值变量之间的关系——pairplot
sns.pairplot(cleaned_data)
如果要根据种类进行细分:
sns.pairplot(cleaned_data, hue=‘species’)
补充
.astype()

astype() 参数:目标数据类型。
返回一个新的 Series(如果是对 DataFrame 的某一列操作)或 DataFrame(如果是对整个 DataFrame 操作),其数据类型已经按照指定的参数进行了转换。原始的 Series 或 DataFrame 并不会被直接修改。
三种赋值方式
cleaned_data = original_data:纯引用赋值
并没有创建一个新的对象,而是让 cleaned_data 和 original_data 指向内存中的同一个对象。也就是说,这两个变量实际上是同一个对象的不同名称。
cleaned_data = original_data.copy():浅拷贝
浅拷贝会创建一个新的对象,但是如果原对象中的元素是可变对象(如列表、字典等),它只会复制引用。也就是说,那么新对象和原对象中的这些可变元素仍然会指向同一个内存地址。
当你修改 cleaned_data 中的子列表时,original_data 中的对应子列表也会被修改。
cleaned_data = original_data.copy(deep=True):深拷贝
深拷贝会递归地复制对象及其所有嵌套的对象,创建一个完全独立的新对象,它们在内存中没有任何共享的部分。
当你修改 cleaned_data 中的子列表时,original_data 不会受到影响。
综上,简单赋值只是创建引用,浅拷贝复制对象结构但共享嵌套的可变对象,而深拷贝则创建一个完全独立的副本。
在原数据中删除行
cleaned_data.drop([3,339], inplace=True)等价于cleaned_data = cleaned_data.drop([3,339])
当使用 inplace=True 时,drop 方法会直接在原 DataFrame 上进行修改,不会返回新的对象。
替换元素
replace 是 pandas 中 Series 和 DataFrame 对象都有的一个方法,其作用是将指定的值替换为其他值。
第一个参数 “.” 表示要被替换的值,
第二个参数 np.nan 是 NumPy 库中的 NaN值。所以cleaned_data[‘sex’] = cleaned_data[‘sex’].replace(“.”, np.nan)的意思是把 cleaned_data[‘sex’] 列中所有值为 “.” 的元素替换为 NaN。
饼图
plt.pie(species_count,labels=species_count.index,autopct=“%.1f%%”)
labels不仅可以传Series,还可以传列表等其它可迭代对象。所以这里直接用species_count
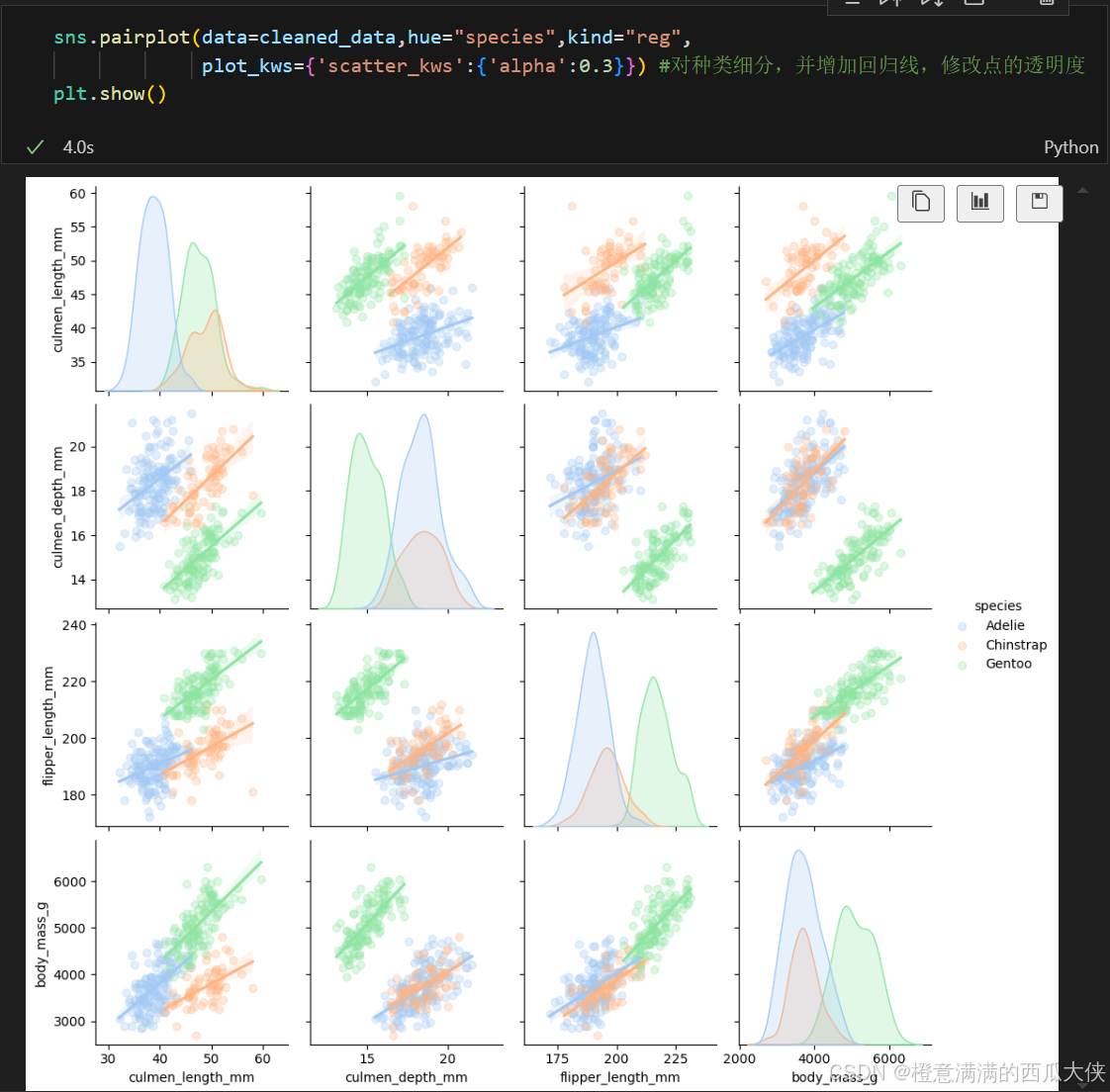
配对图
sns.pairplot(data=cleaned_data,hue=“species”,kind=“reg”, plot_kws={‘scatter_kws’:{‘alpha’:0.3}}) #对种类细分,并增加回归线,修改点的透明度
**kind 参数用于指定非对角线子图(即散点图)的绘制类型。**设置为 “reg” 表示在散点图的基础上添加线性回归拟合线。这样可以帮助我们直观地观察变量之间的线性关系趋势。默认值是kind=“scatter”。
plot_kws={‘scatter_kws’:{‘alpha’:0.3}}
plot_kws 是一个字典类型的参数,用于传递额外的绘图选项,这些选项会被应用到所有的子图上。
其中 ‘scatter_kws’ 是 plot_kws 字典中的一个键,它对应的值也是一个字典,专门用于设置散点图的相关属性。
‘alpha’: 0.3 是 scatter_kws 字典中的一个键值对,alpha 表示透明度,取值范围是 0 到 1,0 表示完全透明,1 表示完全不透明。这里设置为 0.3,意味着散点图中的数据点会有一定的透明度,当数据点比较密集时,使用较低的透明度可以避免数据点相互遮挡,更清晰地展示数据的分布情况。单个散点图直接加上’alpha’: 0.3参数就好。