珠海手机网站建设sem招聘
read_csv()函数不仅是R语言中的一个读取csv文件的函数,也是pandas库中的一个函数。pandas是一个用于数据分析和处理的python库。它的read_csv函数可以读取csv文件里的数据,并将其转化为pandas里面的DataFrame对象。它由很多参数可以设置,例如分隔符、编码、列名、索引等。
文章目录
- read_csv函数的相关参数
- 路径问题
- 解决方案
- 第一种:
- 第二种:
read_csv函数的相关参数
pd.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],sep=',',delimiter=None,header='infer',names=None,index_col=None,usecols=None,squeeze=False,prefix=None,mangle_dupe_cols=True,dtype=None,engine=None,converters=None,true_values=None,false_values=None,skipinitialspace=False,skiprows=None,skipfooter=0,nrows=None,na_values=None,keep_default_na=True,na_filter=True,verbose=False,skip_blank_lines=True,parse_dates=False,infer_datetime_format=False,keep_date_col=False,date_parser=None,dayfirst=False,cache_dates=True,iterator=False,chunksize=None,compression='infer',thousands=None,decimal: str = '.',lineterminator=None,quotechar='"',quoting=0,doublequote=True,escapechar=None,comment=None,encoding=None,dialect=None,error_bad_lines=True,warn_bad_lines=True,delim_whitespace=False,low_memory=True,memory_map=False,float_precision=None,
)
虽然这个参数的数量着实让人头痛,不过我们实际需要用到的往往只有前几个,所以不需要全部记忆。
参考示例:
# 导入pandas库
import pandas as pd# 读取CSV文件
df = pd.read_csv("data.csv")# 打印DataFrame对象
print(df)
路径问题
我们有时候使用read_csv函数的时候,往往会遇到报错,报错位置直指路径,报错内容为ValueError: embedded null character。遇到这种情况往往是因为我们的路径使用了'\'而没有在前面加r。具体情形如下图所示。
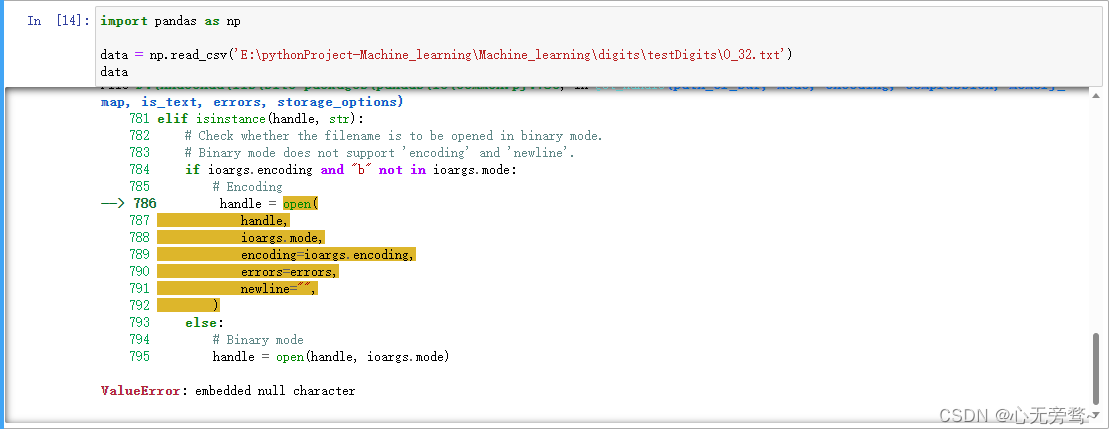
往往遇到这种情况,我们可以使用两种方法解决该问题。
解决方案
第一种:
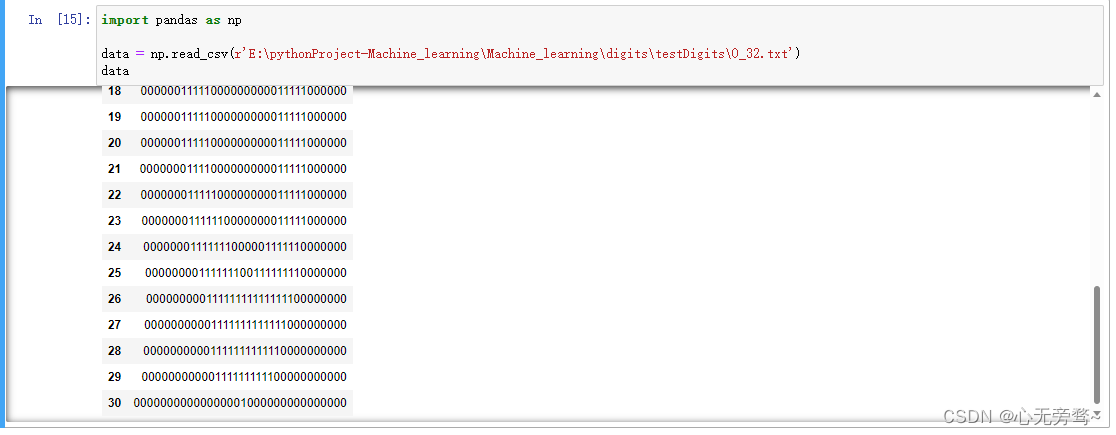
方法:在路径前面加r
原因:因为在python字符串中,'\'具有转义的含义,路径前面加r是为了保持路径在读取时不被漏读,错读。如'\t'可代表TAB,'\n'可代表换行。加r可以使得'\'不背解读为转义字符。
加了r以后我们可以发现read_csv函数可以找到数据集的位置被读取它。效果如下:
第二种:
方法:将路径中的'\'前面再加一个'\',也就是双斜杠。
原因:这样就算在路径读取的时候,系统把'\'当做转义字符处理,我们也还有一个'\'可以用来是read_csv函数读取到数据集文件的位置。
操作结果如下: