武汉手机网站建设品牌hao123文件在哪里
在本篇博客中,我们将探讨如何使用wxPython和PyMuPDF库创建一个简单的Bokeh应用程序,用于选择PDF文件并提取指定页面的内容,并将提取的内容显示在文本框中。
C:\pythoncode\new\pdfgetcontent.py
准备工作
首先,确保你已经安装了以下库:
- wxPython:用于创建桌面应用程序界面。
- PyMuPDF:用于处理PDF文件和提取页面内容。
你可以使用以下命令来安装这些库:
pip install wxPython pymupdf
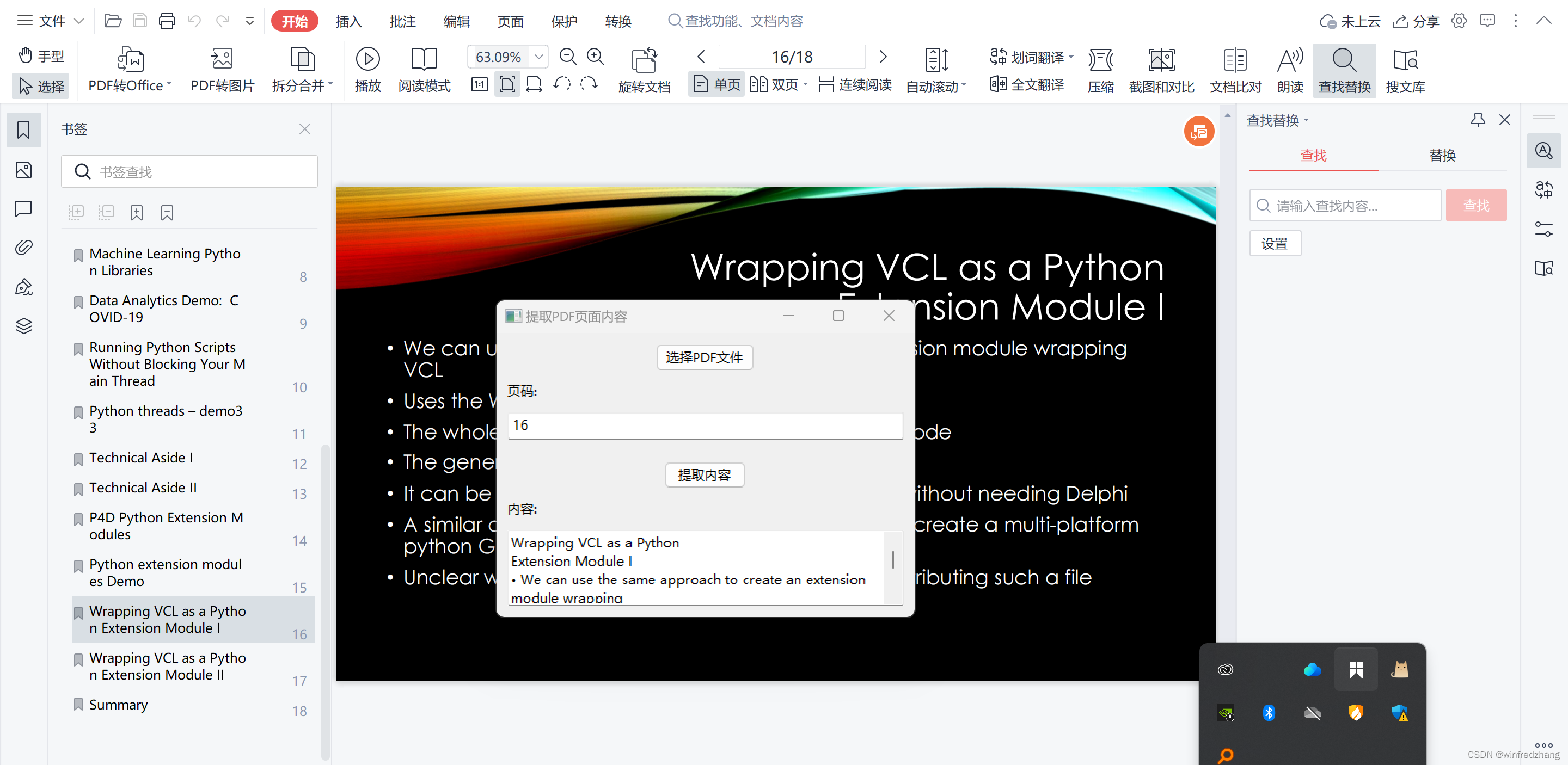
创建应用程序界面
我们将使用wxPython来创建应用程序的图形界面。在应用程序窗口中,我们将添加一个选择按钮,一个页码输入框,一个提取按钮和一个文本框用于显示提取的内容。
def __init__(self):super().__init__(None, title="提取PDF页面内容", size=(400, 300))panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)select_button = wx.Button(panel, label="选择PDF文件")select_button.Bind(wx.EVT_BUTTON, self.on_select_pdf)vbox.Add(select_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)page_label = wx.StaticText(panel, label="页码:")vbox.Add(page_label, proportion=0, flag=wx.LEFT, border=10)self.page_input = wx.TextCtrl(panel)vbox.Add(self.page_input, proportion=0, flag=wx.EXPAND | wx.ALL, border=10)extract_button = wx.Button(panel, label="提取内容")extract_button.Bind(wx.EVT_BUTTON, self.on_extract_content)vbox.Add(extract_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)content_label = wx.StaticText(panel, label="内容:")vbox.Add(content_label, proportion=0, flag=wx.LEFT, border=10)self.content_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE | wx.TE_READONLY)vbox.Add(self.content_text, proportion=1, flag=wx.EXPAND | wx.ALL, border=10)panel.SetSizer(vbox)def on_select_pdf(self, event):dialog = wx.FileDialog(self, message="选择PDF文件", wildcard="PDF files (*.pdf)|*.pdf", style=wx.FD_OPEN)if dialog.ShowModal() == wx.ID_OK:self.pdf_path = dialog.GetPath()dialog.Destroy()
在上述代码中,我们创建了一个名为PDFContentExtractor的类,继承自wx.Frame。在该类中,我们使用Bokeh创建了一个包含选择按钮、页码输入框、提取按钮和内容文本框的布局。我们为选择按钮和提取按钮绑定了相应的事件处理方法。
处理PDF文件选择和内容提取
我们使用wxPython的文件对话框来选择PDF文件,并使用PyMuPDF库来打开和处理PDF文件。当用户选择PDF文件并点击提取按钮时,我们将提取指定页码的内容,并将其显示在内容文本框中。
import wx
import fitzclass MyFrame(wx.Frame):def __init__(self):super().__init__(None, title="提取PDF页面内容", size=(400, 300))panel = wx.Panel(self)vbox = wx.BoxSizer(wx.VERTICAL)select_button = wx.Button(panel, label="选择PDF文件")select_button.Bind(wx.EVT_BUTTON, self.on_select_pdf)vbox.Add(select_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)page_label = wx.StaticText(panel, label="页码:")vbox.Add(page_label, proportion=0, flag=wx.LEFT, border=10)self.page_input = wx.TextCtrl(panel)vbox.Add(self.page_input, proportion=0, flag=wx.EXPAND | wx.ALL, border=10)extract_button = wx.Button(panel, label="提取内容")extract_button.Bind(wx.EVT_BUTTON, self.on_extract_content)vbox.Add(extract_button, proportion=0, flag=wx.ALIGN_CENTER | wx.ALL, border=10)content_label = wx.StaticText(panel, label="内容:")vbox.Add(content_label, proportion=0, flag=wx.LEFT, border=10)self.content_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE | wx.TE_READONLY)vbox.Add(self.content_text, proportion=1, flag=wx.EXPAND | wx.ALL, border=10)panel.SetSizer(vbox)def on_select_pdf(self, event):dialog = wx.FileDialog(self, message="选择PDF文件", wildcard="PDF files (*.pdf)|*.pdf", style=wx.FD_OPEN)if dialog.ShowModal() == wx.ID_OK:self.pdf_path = dialog.GetPath()dialog.Destroy()def on_extract_content(self, event):page_num = int(self.page_input.GetValue())self.extract_page_content(page_num)def extract_page_content(self, page_num):doc = fitz.open(self.pdf_path)if page_num < 1 or page_num > doc.page_count:wx.MessageBox("无效的页码!", "错误", wx.OK | wx.ICON_ERROR)returnpage = doc.load_page(page_num - 1)text = page.get_text()self.content_text.SetValue(text)doc.close()if __name__ == '__main__':app = wx.App()frame = MyFrame()frame.Show()app.MainLoop()# ...class PDFContentExtractor(wx.Frame):# ...def on_select_pdf(self):dialog = wx.FileDialog(self, message="选择PDF文件", wildcard="PDF files (*.pdf)|*.pdf", style=wx.FD_OPEN)if dialog.ShowModal() == wx.ID_OK:self.pdf_path = dialog.GetPath()dialog.Destroy()def on_extract_content(self):page_num = int(self.page_input.value)self.extract_page_content(page_num)def extract_page_content(self, page_num):doc = fitz.open(self.pdf_path)if page_num < 1 or page_num > doc.page_count:self.content_text.text = "无效的页码!"returnpage = doc.load_page(page_num - 1)text = page.get_text()self.content_text.text = textdoc.close()# ...
在上述代码中,我们使用wx.FileDialog对话框来选择PDF文件,并将选择的文件路径存储在self.pdf_path变量中。
在on_extract_content方法中,我们获取输入框中的页码,并调用extract_page_content方法来提取指定页码的内容。
在extract_page_content方法中,我们使用PyMuPDF打开并读取PDF文件。然后,我们通过doc.load_page方法加载指定页码的页面,并使用get_text方法获取该页的文本内容。最后,我们将提取的内容设置到文本框content_text中。
运行应用程序
if __name__ == '__main__':app = wx.App()frame = PDFContentExtractor()frame.Show()app.MainLoop()
在上述代码中,我们创建了一个wx.App实例,并实例化了PDFContentExtractor类。然后,我们显示应用程序窗口,并通过调用app.MainLoop()来启动应用程序的事件循环。
结论
通过本篇博客,我们学习了如何使用wxPython和PyMuPDF创建用于选择PDF文件并提取指定页面的内容。我们还了解了如何使用Bokeh来创建交互式应用程序界面,并通过事件处理方法来处理用户的选择和操作。