如何建设一个国外网站,求购买链接,wordpress 主题 新闻_,市民服务中心网站建设1.简介 1.开源的分布式数据生态项目 ShardingSphere-JDBC:轻量级Java框架ShardingSphere-Proxy:数据库代理ShardingSphere-Sidecar(规划中):Kubernetes的云原生数据库代理 2.使用版本:ShardingSphere5.1.1 1.数据库集群架构 1.出现… 1.简介
- 1.开源的分布式数据生态项目
ShardingSphere-JDBC:轻量级Java框架ShardingSphere-Proxy:数据库代理ShardingSphere-Sidecar(规划中):Kubernetes的云原生数据库代理
- 2.使用版本:
ShardingSphere5.1.1
1.数据库集群架构
- 1.
出现原因:单个数据库服务器无法满足海量数据加海量用户的业务需求 - 2.
解决方式:采用数据库集群架构提高应用程序的性能 - 3.
具体实现
1.读写分离
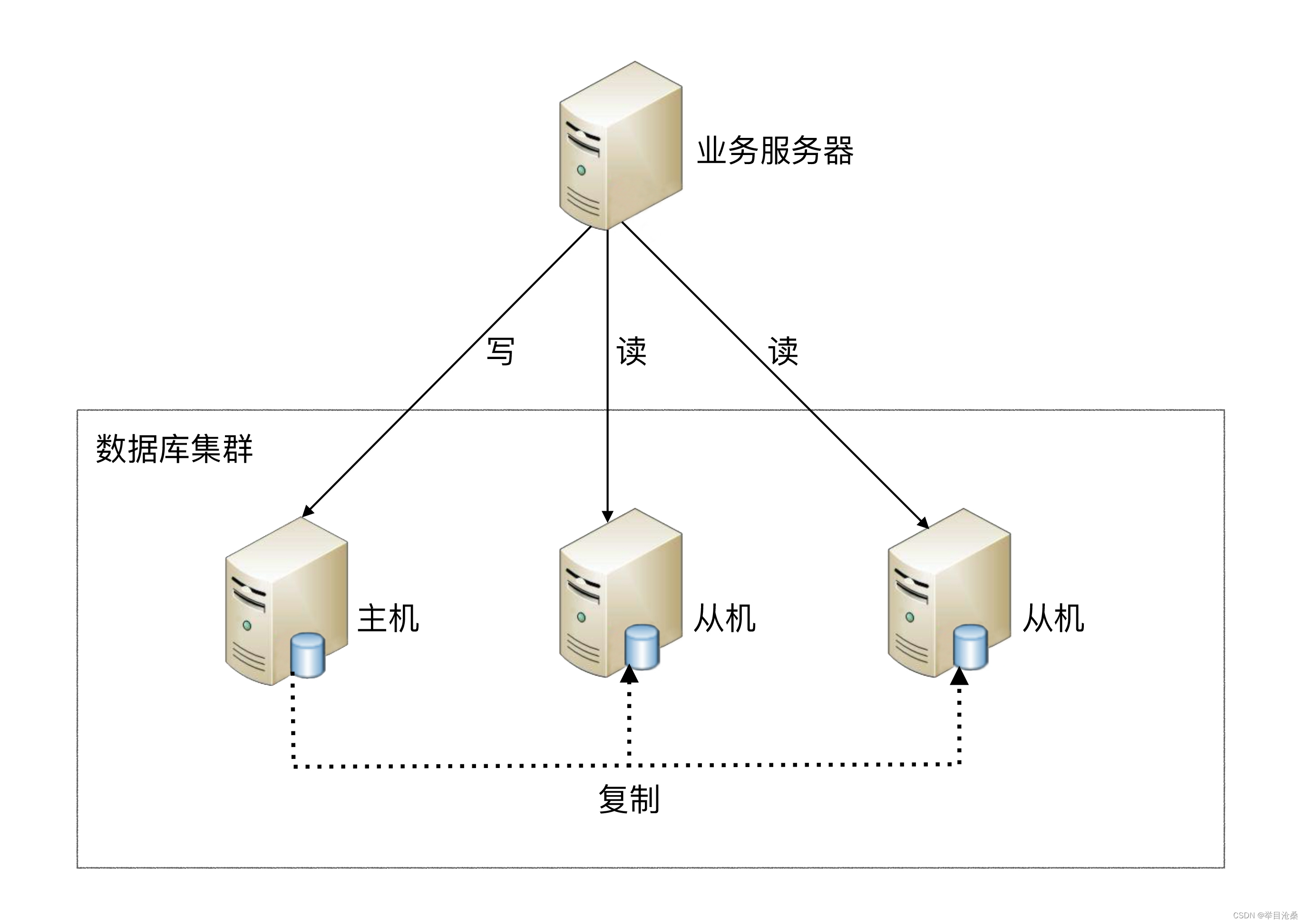
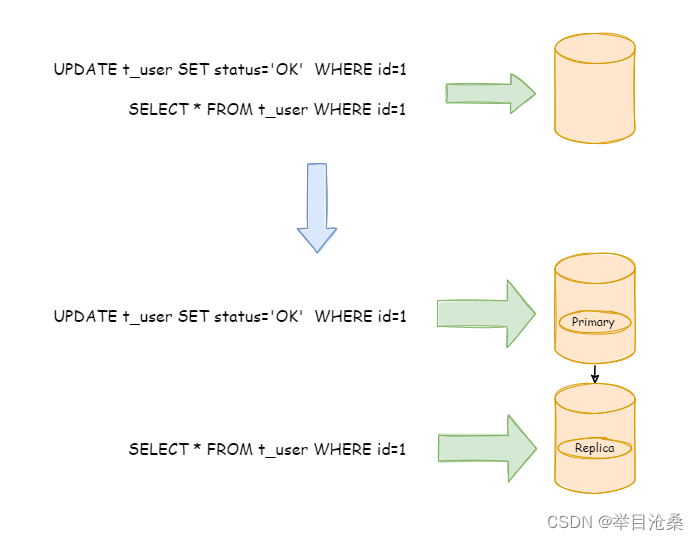
- 1.
原理:将数据库读写操作分散到不同的节点上,分散了数据库读写的压力 - 2.
主机:负责事务性的增删改操作;从机:负责查询操作 - 3.
读写分离机制建立在数据库主从复制的基础上 - 4.
优点:通过读写分离可以有效避免数据更新导致的行锁,也可将查询负载均衡的分散到多个从机中,从而提高查询性能 - 5.
问题 - 1.主机向从机复制数据的过程中会有时间的延迟,如果将数据写入主机,立即从从机读取数据,这时数据可能还未从主机完全复制到从机,所以会出现
数据不一致问题,即CAP定理 - 2.
读写分离分散了数据库读写压力,但没有分散存储压力,为了业务数据存储的需求,需将存储分散到多台数据库服务器
1.CAP定理
- 1.
定义:分布式系统中,当涉及读写操作时,只能保证一致性(Consistence),可用性(Availability),分区容错性(Partition Tolerance)三者中的两个 - 1.
C:一致性,对某个指定的客户端,读操作保证能够返回最新的写操作结果,即读写结果一致 - 2.
A:可用性,非故障的节点在合理的时间内返回合理的响应(非错误和超时的响应) - 3.
P:分区容错性,当出现网络分区(多个服务器数据交换)后,系统能够继续履行职责(继续执行,可返回超时或历史数据)
- 2.
特点:实际设计过程中,每个系统不可能只处理一种数据,有的数据必须选择CP,有的数据必须选择AP,分布式系统理论上不可能选择CA - 3.
CAP理论中的C在实践中不可能完美实现,数据复制的过程中,节点N1和节点N2的数据并不一致(强一致性);即使无法做到强一致性,但应用可以采用合适的方式达到最终一致性 - 1.
基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用性,保证核心可用 - 2.
软状态(Soft State):允许系统存在中间状态,该中间状态不会影响系统的整体可用性,这里的中间状态就是CAP理论中的数据不一致 - 3.
最终一致性(Eventual Consisitency),系统中的所有数据副本经过一定时间后,最终能够达到一致的状态
1.CP
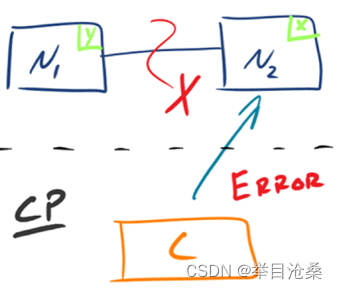
- 1.如图所示,为了保证
一致性,当发生分区现象(丢包)后,N1节点上数据已经更新到y,但由于N1和N2之间的复制通道中断,数据y无法同步到N2,N2节点上的数据还是x - 2.此时客户端
c访问N2时,N2需要返回Error,提示客户端C系统现在发生了错误,该处理方式违背了可用性的要求,此时CAP三者只能满足CP
2.AP
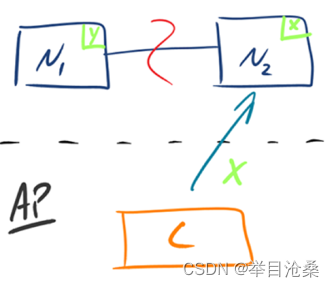
- 1.如图所示,为了保证
可用性,当发生分区现象后,N1节点上的数据已经更新到y,但由于N1和N2之间的复制通道中断,数据y无法同步到N2,N2节点上的数据还是x - 2.此时客户端
C访问N2时,N2将当前自己拥有的数据x返回给客户端C,而实际当前最新的数据是y,不满足一致性的要求,此时CAP只能满足AP.
2.数据分片
- 1.
读写分离问题:读写分离分散了数据库读写压力,从而缓解了单台服务器的访问压力,但没有分散存储压力,为了满足业务数据存储需求,需将存储分散到多台数据库服务器 - 2.
数据分片定义:将存放在单一数据库或表中的数据分散地存放至多个数据库或表中,以达到提升性能瓶颈以及可用性的效果 - 3.数据分片的
拆分方式 - 4.
适用场景:《阿里开发手册》建议单表超过500万条记录或单表大小超过2GB需要考虑分库分表

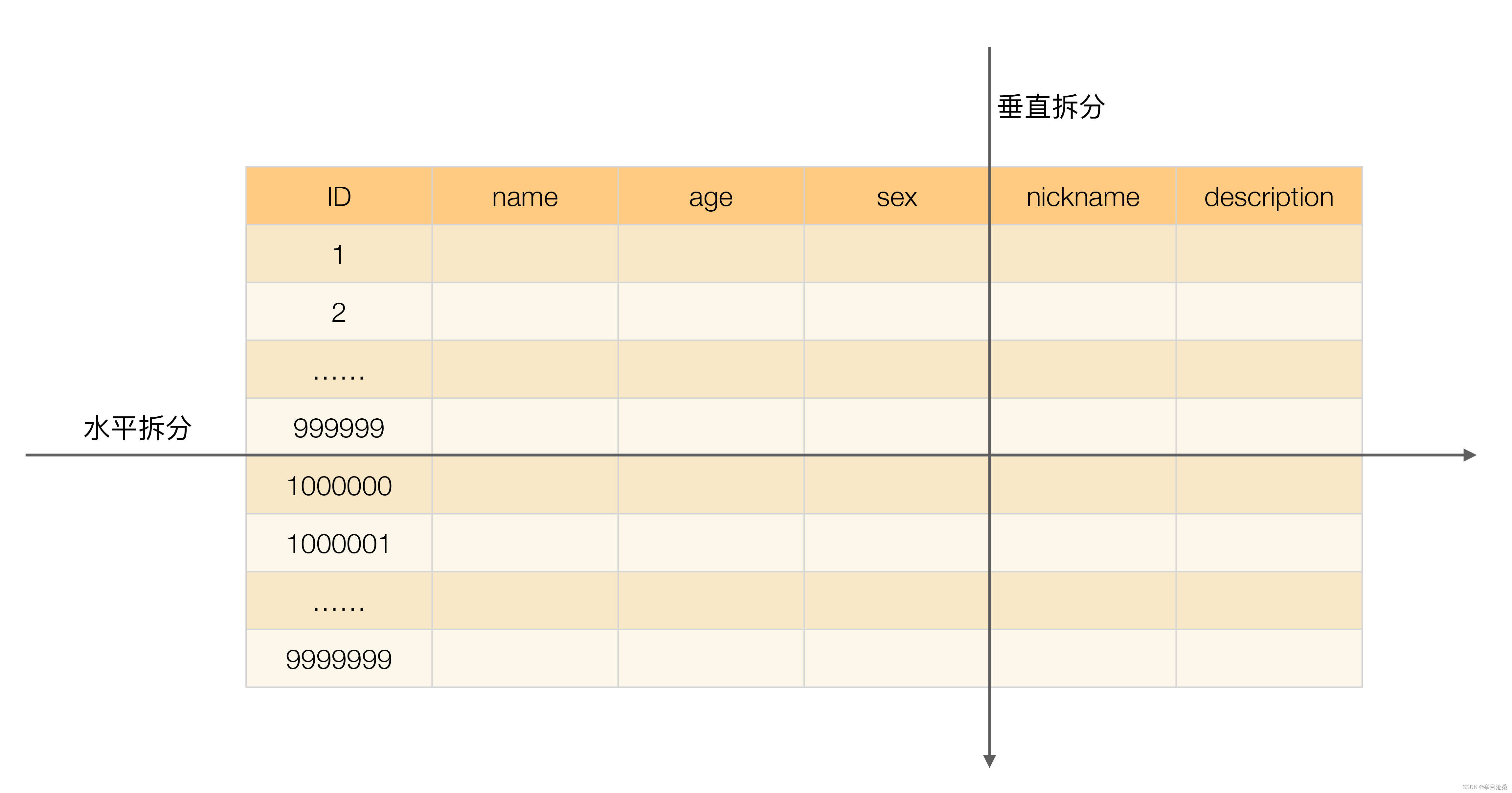
1.垂直分片
- 1.
定义:按照业务拆分的方式称为垂直分片/纵向拆分 - 2.
垂直分片可细分为
1.垂直分库
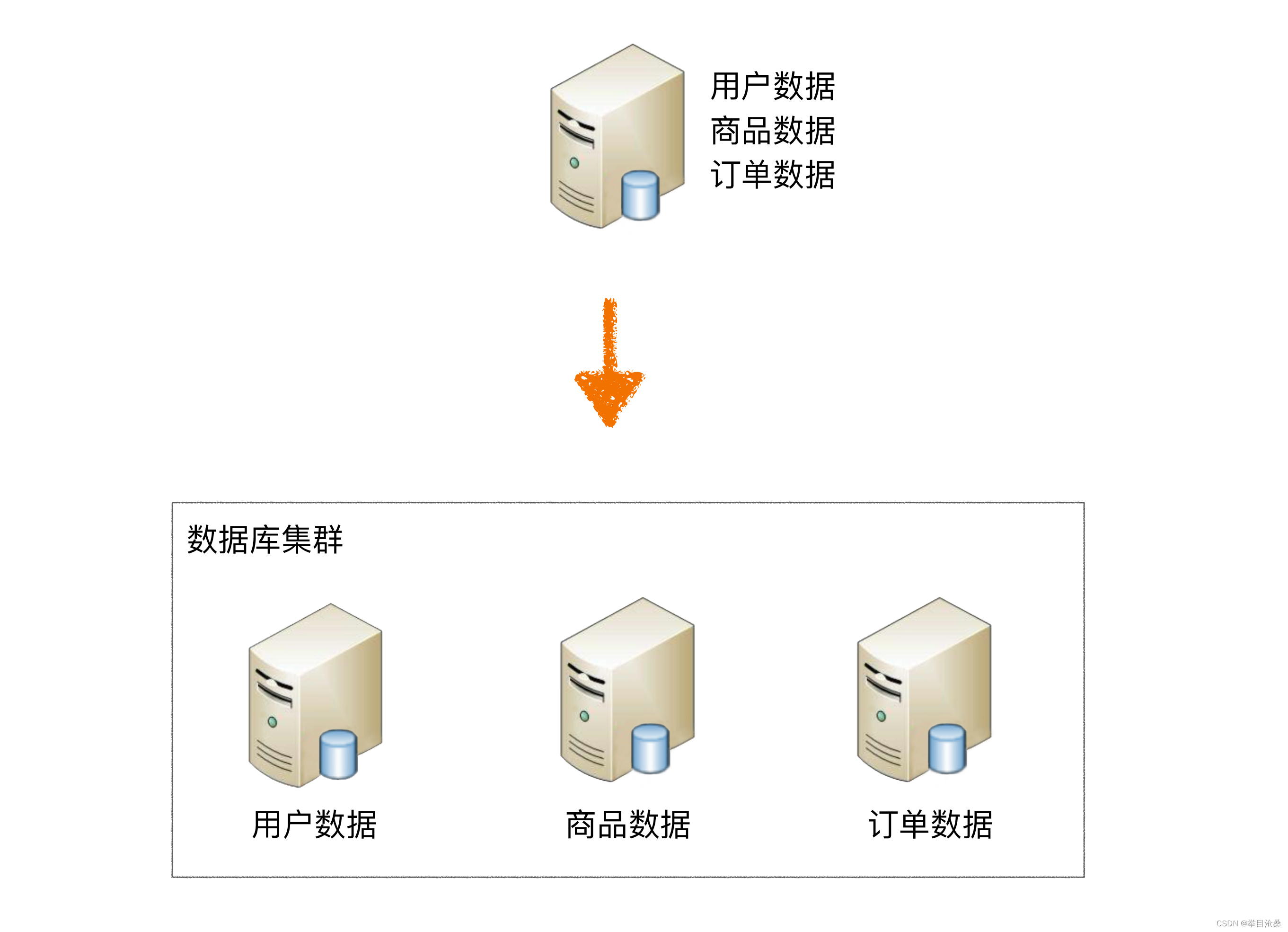
- 1.
定义:核心理念是专库专用 - 1.
拆分之前:一个数据库由多个数据表构成,每个表对应着不同的业务 - 2.
拆分之后:按照业务将表进行归类,分布到不同的专用数据库,从而将压力分散至不同的数据库
- 2.
问题:垂直分库可以缓解数据库数据量和访问量的问题,但无法处理单表数据量过大问题,此时需要水平分片进一步处理
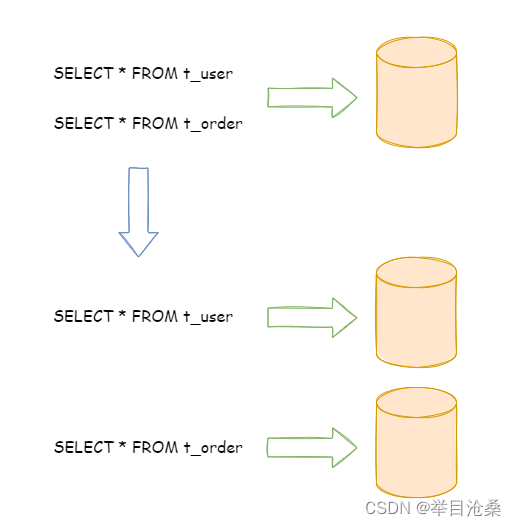
2.垂直分表
- 1.
定义:核心理念是专表专用 - 1.
拆分之前:一个数据表由多个字段构成,每个字段对应着不同的业务 - 2.
拆分之后:按照业务将字段进行归类,分布到不同的专用数据表,从而将压力分散至不同的数据表
- 2.
问题 - 1.垂直分表可以缓解数据表访问量和占用量的问题,但无法处理单表数据量过大问题,此时需要
水平分片进一步处理 - 2.垂直分表会引入额外的复杂度,原来只要一次查询,现在需要两次查询
- 3.
适用范围:垂直分表适合将表中不常用的列或是占了大量空间的列拆分出去 - 4.
注意:垂直分表对应的主键id应该保持一致
2.水平分片
- 1.
定义:通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中的方式称为水平分片/横向拆分 - 2.
水平分片可细分为
1.水平分库
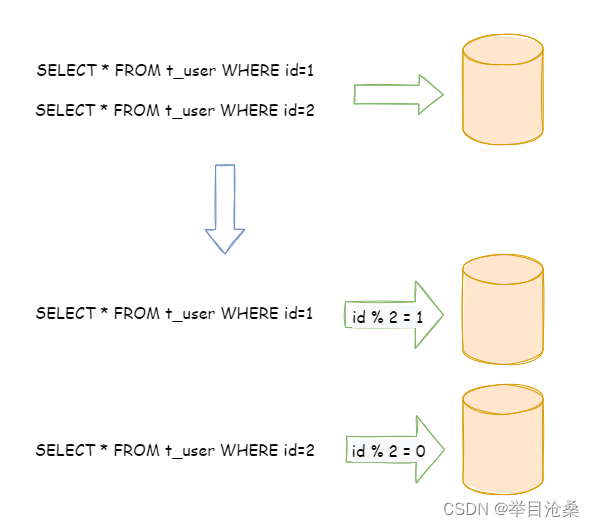
- 1.
定义:相对于垂直分库,不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库中,每个数据库的分片仅包含数据的一分部(例:根据主键分片,偶数主键的记录放入0库,奇数主键的记录放入1库) - 2.单表进行切分后,是否将多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定
- 3.
适用场景:如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就需要将多个表分散在不同的数据库服务器中
2.水平分表
- 1.
定义:相对于垂直分表,不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个表中,每个数据表的分片仅包含数据的一分部(例:根据主键分片,偶数主键的记录放入0表,奇数主键的记录放入1表) - 2.
适用范围:水平分表适合表行数特别大的表
- 3.
注意 - 1.单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升;如果性能能够满足业务要求,可不拆分到多台数据库服务器,因为业务分库也会引入更多复杂性
- 2.将拆分的表引入多台数据库会更复杂(例:分布式事务,跨库关联,数据库成本)
3.读写分离和数据分片
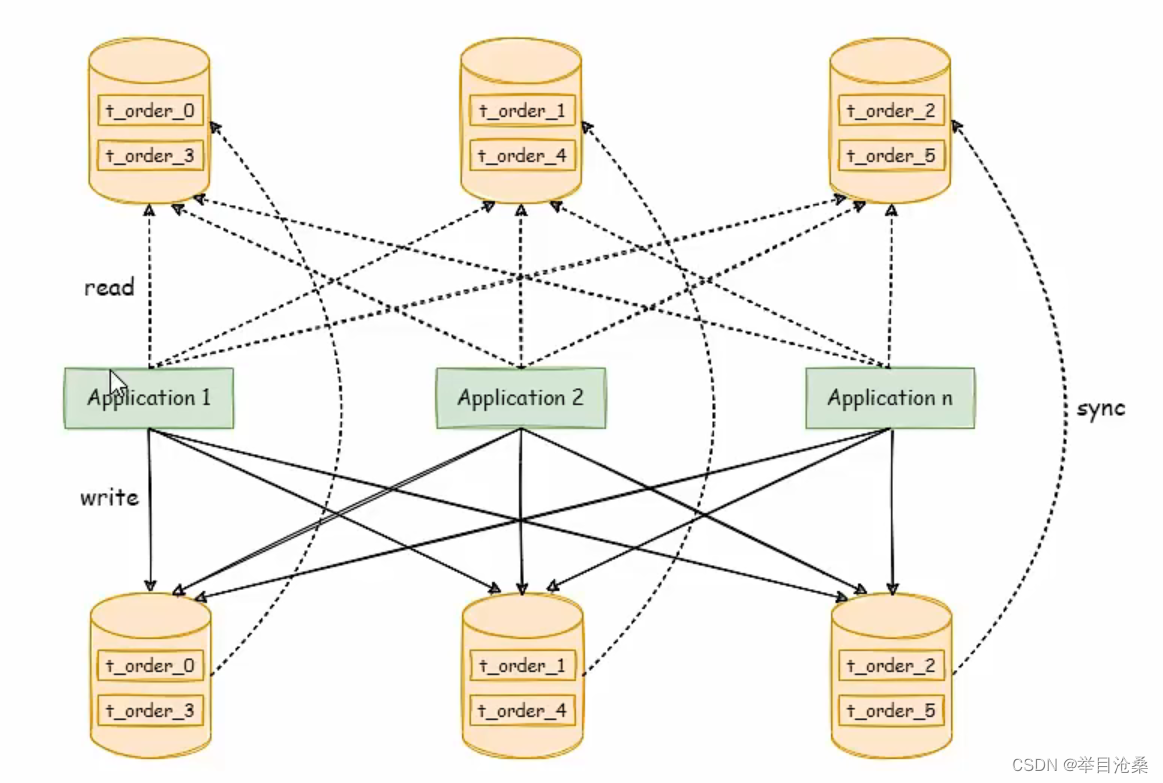
- 1.上图展示将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系
1.实现方式
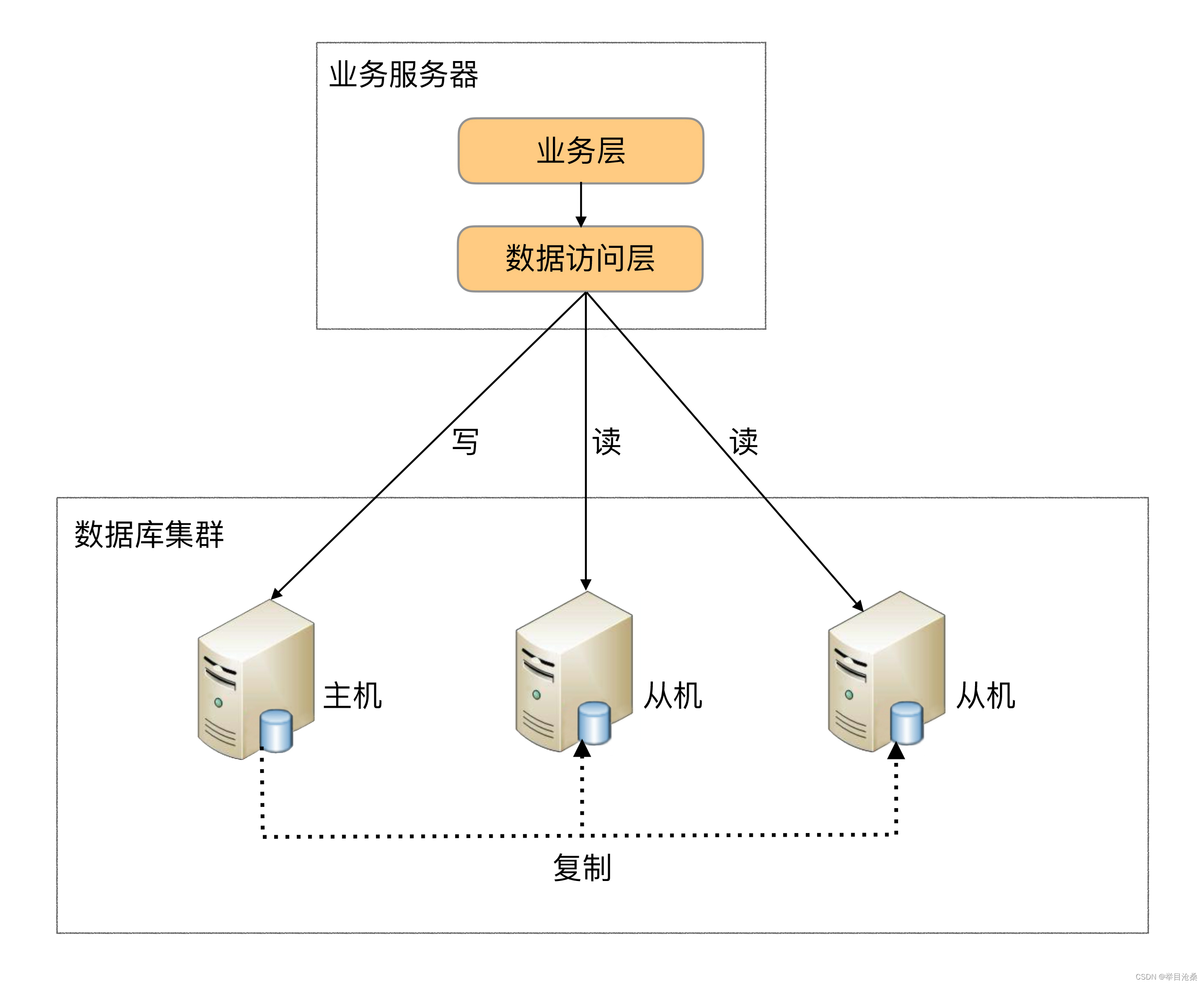
1.程序代码封装
- 1.定义:指在代码中抽象一个
数据访问层(或中间层封装),对程序进行一个封装,让数据访问层直接去访问不同数据库集群中的数据源,实现读写分离操作和数据库服务器连接的管理
2.中间件封装
- 1.中间件封装是指的是独立一套系统出来提供数据访问层的功能,从而实现读写操作分离和数据库服务器连接的管理
- 2.对于程序服务器而言,访问中间件和访问数据库没有区别
- 3.常用的中间件有
ShardingSphere和MyCat,其中已经封装好了数据访问层供程序使用 - 4.
Apache ShardingSphere既提供了程序级别也提供了中间件级别两种解决方案;MyCat只提供了中间件解决方案
2.ShardingSphere JDBC
1.简介
- 1.
ShardingSphere JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务,类似生成一个数据访问层,它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架 - 使用与任何基于JDBC的ORM框架,如:JPA,Hibetnate,mybatis,Spring JDBC Template或直接使用JDBC
- 支持任何第三方的数据库连接池,如:DBCP,C3P0,BoneCP,HikariCP等
- 支持任意实现JDBC规范的数据库,目前支持MySQL,PostgreSQL,Oracle,SQLServer以及任何可使用JDBC访问的数据库
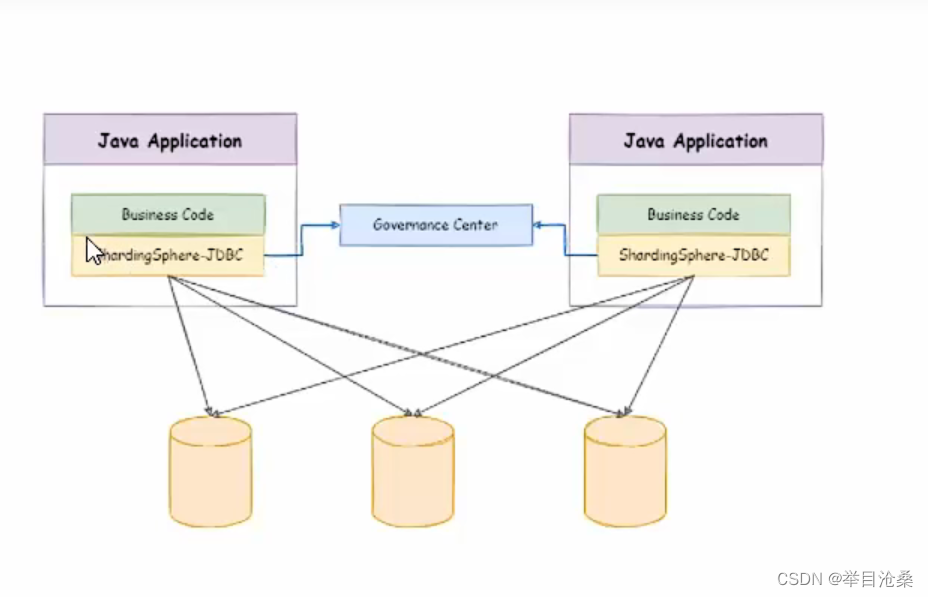
- 如果应用程序也是集群模式可以采用服务治理组件G… Center,例Zookeeper
ShardingSphere-Proxy
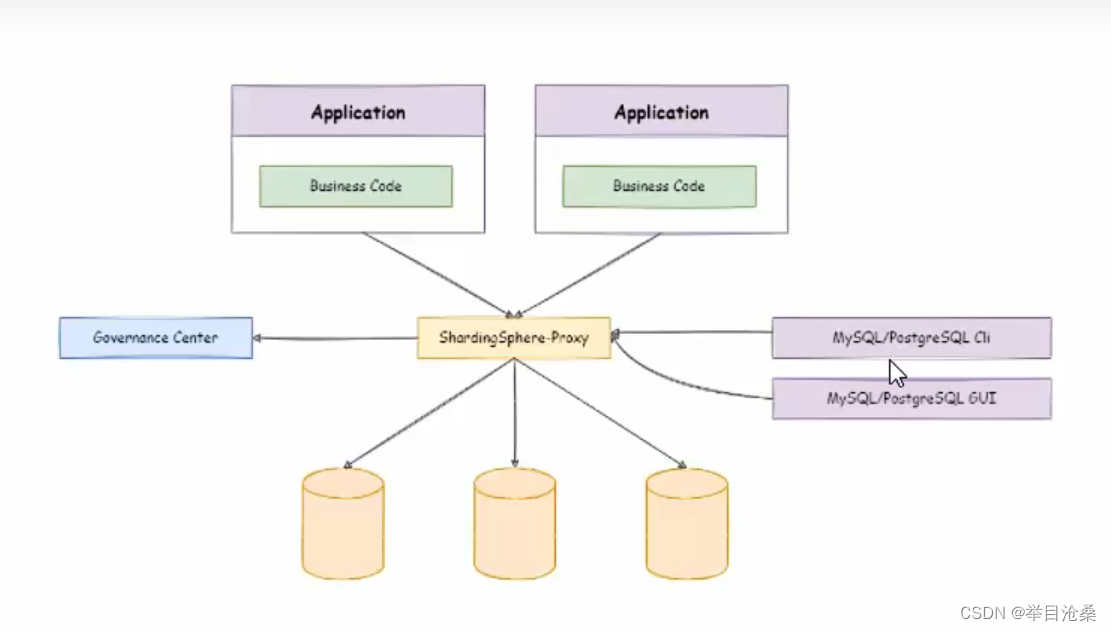
- 定位为透明化的数据库代理器,即只是一个中间件,提供了封装了数据库二进制协议的服务端版本,用于完成对异构语言(即非Java的项目)的支持,目前提供Mysql和PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client,MySQL Workbench,Navicat等)操作数据,对DBA更加友好
- 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用
- 适用于任何兼容MySQL/PostgreSQL协议的客户端
安装Docker
- Docker可以运行在Windows,Mac,CentOS,Ubuntu等操作系统上
- Docker支持以下的CentOS版本
- 1.CentOS7(64-bit)
- 2.CentOS6.5(64-bit)或更高的版本
- 目前,CentOS仅发行版本中的内核Docker
- Docker运行在CentOS7上,要求系统为64位,系统内核版本为3.10以上
- Docker运行在CentOS-6.5或更高的版本的CentOS上,要求系统为64位,系统内核版本为2.6.37或更高版本
- 2.查看系统内核
- uname命令用打印当前系统相关信息
- uanme -r
- 3.查看已安装的CentOs的版本信息
- cat /etc/redhat-release
3.CentOS7安装docker
- 1.安装需要的软件包
- yy -utils提供了yy-config-manager相关功能,device-mapper-persistent-data和lvm2是设备映射器驱动程序所需要的
- yum install -y yuim-utils \ device-mapper-persistent-data \ lvm2
- 2.设置docker下载镜像
- 推荐阿里云下载地址
- yum-config-manager --add-repo http://mirrors
- 3.更新yum软件包索引
- 我们在更新或配置yum源之后,通常都会使用yum makecache生成缓存,这个命令是将软件包信息提前在本地缓存一份,用来提高搜索安装软件的速度
- yum makecache fast
- 4.安装docker ce
- yum install -y docker -ce
- 5.启动docker
- systemctl start docker
- 6.版本验证
- docker version
- 7.设置开机启动
- 查看服务是否自动启动(enabled,是;disabled,否)
- systemctl list-unit-files | grep docker.service
- sysmctl enable docker
- systemctl deamon-reload
- systemctl diable docker
- systenctl deamin-reload
- 卸载
- systemctl stop docer
- yum remove -y docker -ce
- rm -rf /var/lib/docker