广州网站建设腾虎windows系统优化软件
一、概要

Kafka作为一种高吞吐量的分布式发布订阅消息系统,在消息应用中广泛使用,尤其在需要实时数据处理和应用程序活动跟踪的场景,kafka已成为首选服务;在Kafka2.8之前,Kafka强依赖zookeeper来来负责集群元数据的管理,这也导致当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。2.8版本之后,kafka3.x开始提供KRaft(Kafka Raft,依赖Java 8+ )模式,开始去除对zookeeper的依赖。最新的3.5版本中,Kafka依然兼容zookeeper Controller,但Kafka Raft元数据模式,已经可以在不依赖zookeeper的情况下独立启动Kafka了。
kraft模式的优势:
1、更简单的部署和管理——通过只安装和管理一个应用程序,Kafka 现在的运营足迹要小得多。这也使得在边缘的小型设备中更容易利用 Kafka;
2、提高可扩展性——KRaft 的恢复时间比 ZooKeeper 快一个数量级。这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万;
3、更有效的元数据传播——基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能。另外它还支持元数据主题的快照。
资料链接:官网kraft、kafka_jira
二、拓扑
2.1、早期拓扑


老controller选举原理: 只有一个broker可以当选Controller,当Controller在的broker宕机后,其他Broker可以竞争当选Controller。

Kafka是通过使用epoch number(纪元编号,也称为隔离令牌)来完成的。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper 的条件递增操作获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较旧(较小)epoch number的消息,就会忽略它们,即Broker根据最大的epoch number来区分当前最新的controller。
常见几种副本状态:
New:controller刚刚创建副本时副本的状态,此状态的副本只能成为follower副本
Online:启动副本后变更为该状态,此状态的副本既可以成为follower副本也可以成为leader副本
Offline:当副本所在的broker宕机后,副本的状态就会转变为Offline
ReplicaDeletionStarted:当Kafa集群开启了topic删除且收到某个topic的删除命令时,该topic下的副本就会进入该状态
ReplicaDeletionSuccessful:当副本成功删除以后,副本就会进入该状态
ReplicaDeletionIneligible:当有副本删除失败时,副本就会进入该状态,等待controller的重试
NonExistent:当副本成功删除后,副本进入该状态,或者Topic刚刚创建副本并未建立时,副本就处于该状态。
当Kafka Topic刚刚创建时,该Topic的副本处于NonExistent状态,此时controller加载Zookeeper中该Topic每个分区的副本信息到内存中,同时将副本更新为New状态,之后controller选择分区的第一个副本作为leader副本并设置所有副本进入ISR,然后再Kafka中持久化该决定。
当确定了分区副本以及leader以后,controller会将这些信息发送给各个副本,同时将副本状态同步给所有的broker。上述操作完成以后,副本就会进入Online状态。
当开启了Topic删除操作,controller会停止所有副本,如果是follower副本将停止向leader副本fetch数据,如果是leader副本,controller会设置该分为的leade为NO_LEADER,之后副本进入Offline状态。紧接着,controller会将副本的状态变为ReplicaDeletionStarted状态表明开始进行Topic删除。controller会向所有的副本发出删除请求,请求他们删除本地的副本数据,当所有副本删除成功以后,便会进入ReplicaDeletionSuccessful状态。假设删除过程中有其中一个副本删除失败,则会进入ReplicaDeletionIneligible状态,等待controller的重试。同时处于ReplicaDeletionSuccessful状态会自动变为NonExistent状态,同时controller的上下文缓存会清除这些副本信息。
以下是分区状态:
NonExistent:表明分区不存在或分区已被删除
New:一旦分区被创建,分区便处于该状态。此时Kafka已经确定了分区列表,但是还没有选出Leader和ISR。
Online:一旦分区leader被选出,则进入该状态,表示分区可以正常工作
Offline:当分区leader所在的broker宕机以后则会进入该状态,表明分区无法正常工作
当创建Topic时,controller负责创建分区对象,首先会短暂的将所有分区置为NonExistent状态,之后读取Zookeeper中的副本分配方案,然后令分区进入New状态。处于New状态的分区当选出Leader副本和ISR时,将会进入Online状态。
若用户发起了删除Topic操作,分区会进入NonExistent状态,并且还会开启分区下的副本删除操作。如果是关闭broker操作或者宕机,controller会判断broker是否是分区leader,如果是则需要开启新一轮的分区leader选举然后将分区状态改回Online状态。
2.2、kRaft controller拓扑



kafka kraft模式集群:必须是奇数节点,3节点最大容错1个,5节点容错2个


KRaft集群中,所有控制器代理都维护一个保持最新的内存元数据缓存,以便任何控制器都可以在需要时接管作为活动控制器(active controller),所有brokers都与控制器进行通信,其中活动控制器将处理与其他brokers通信对元数据的更改。KRaft 基于 Raft 共识协议,该协议作为 KIP-500 的一部分引入 Kafka,并在其他相关 KIP 中定义了更多细节。活动控制器是kafka kraft集群内部元数据主题的单个分区的leader,其他控制器是副本follower,brokers是副本观察者。因此,不是controlle将元数据更改广播给其他控制器或brokers,而是它们各自主动获取更改。这使得保持所有控制器和brokers同步非常有效,并且还缩短了broker和控制器的重启时间。
在 KRaft 模式下,集群元数据(反映所有控制器管理资源的当前状态)存储在名为__cluster_metadata. KRaft 使用这个主题在控制器和代理节点之间同步集群状态更改。KRaft 模式下,Kafka 集群可以以专用或共享模式运行。在专用模式下,一些节点将其process.roles配置设置为controller,而其余节点将其设置为broker。对于共享模式,这些节点将process.roles设置为controller, broker,即些节点将执行双重任务。该模式中那个称为“controller”的特殊节点负责管理集群中代理的注册,它一般就是controller.quorum.voters中的第一个节点。Broker 活跃度有两个条件:
1、Brokers must maintain an active session with the controller in order to receive regular metadata updates.而 “active session” depends on the cluster configuration,an active session is maintained by sending periodic heartbeats to the controller. If the controller fails to receive a heartbeat before the timeout configured by broker.session.timeout.ms expires, then the node is considered offline.
2、Brokers acting as followers must replicate the writes from the leader and not fall “too far” behind.
Kradt模式下,the controllers store the cluster metadata in the directory specified in metadata.log.dir/the first log directory。特别注意,新增controller节点时需等待现有的controller提交完成所有数据后:The new controller node should not be formatted and started until the majority of the controllers have all of the committed data. 可通过如下命令来检查确认:kafka-metadata-quorum.sh --bootstrap-server broker_host:port describe --replication,如果显示Lag的值为0就最好,至少保证Lag值对于controllers足够小,或如果leader’s end offset is not increasing, you can wait until the lag is 0 for a majority;如果不是0,要检查下LastFetchTimestamp 和 LastCaughtUpTimestamp这2个值,所有controller的这2个值要尽量接近,即读到的和消费掉的要一致;之后才能执行:bin/kafka-storage.sh format --cluster-id uuid --config server_properties对新controller的元数据存储路径进行格式化;注意,混合模式下,存储格式化会报错:Log directory … is already formatted,这中情况仅出现在混合模式下且原controller 日志路径丢失或损坏的情况下,可执行:bin/kafka-storage.sh format --cluster-id uuid --ignore-formatted --config server_properties ,其他情况不建议使用。控制器用来接收来自其他控制器和borkers的请求。因此,即使服务器没有启用controller角色(即它只是一个broker),它仍然必须定义控制器侦听器以及配置它所需的任何安全属性。配置参考示例:
process.roles=broker
listeners=BROKER://localhost:9092 #broker does not expose the controller listener itself
inter.broker.listener.name=BROKER #区别于下面的controller.listener.names
controller.quorum.voters=0@localhost:9093
controller.listener.names=CONTROLLER #仅用于controller
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL#混合模式
process.roles=broker,controller
listeners=BROKER://localhost:9092,CONTROLLER://localhost:9093 #listeners独立配置用户kafka 客户端访问
inter.broker.listener.name=BROKER #配合上面的与kafka client交互,隔离开controller
controller.quorum.voters=0@localhost:9093
controller.listener.names=CONTROLLER #The controller will accept requests on all listeners defined by controller.listener.names,多个controller时,the first one in the list will be used for outbound requests.
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL

更多参见 KRaft Principal Forwarding。注意:kraft模式下的混合模式多用于开发环境,生产环境不建议使用。混合模式下一个明显的问题就是, controller will be less isolated from the rest of the system,即无法与broker隔离,一个典型场景就是无法单独对controller进行弹性扩展或回滚升级;KRaft模式下,特定的Kafka服务器将被选作为controller;所有被定义候选的controller都会参与元数据的竞选,对已active的controller,其他的controller都充当hot standby 角色;因此,我们常用做法配置process.role 为 broker/controller而不是两者都具备(混合模式);推荐,一个Kafka集群应该使用3个controller就可,超过3个也不推荐。Kafka控制器将集群的所有元数据存储在内存和磁盘上,官方建议知识给内存和磁盘分出各5G空间用来存储这些metadata日志;另外,kraft也有一些限制问题,比如以下功能未在KRaft模式中完全实现:
1、通过管理API配置SCRAM用户
2、支持具有多个存储目录的JBOD配置
3、修改独立KRaft控制器上的某些动态配置
4、委派令牌tokens
KRaft元数据复制过程:

集群元数据存储在 Kafka 主题中,而活动控制器是元数据主题的单个分区的领导者,它将接收所有数据并写入。其他控制器作为follower,将主动获取这些更改。对比传统的副本复制,当需要选举新leader时,是通过仲裁完成的,而不是同步副本集。因此,元数据复制不涉及 ISR。另一个区别是元数据记录在写入每个节点的本地日志时会立即刷新到磁盘。
Kraft 模式 以及 安全认证配置:
SASL/GSSAPI:kerberos认证方式,一般使用随机密码的keytab认证方式,密码是加密的,也是企业里使用最多的认证方式;
SASL/PLAIN:这种方式其实就是一个账号/密码的认证方式,不过它有很多缺陷,比如用户名密码是存储在文件中,不能动态添加,密码明文等等!好处是足够简单;
SASL/SCRAM:针对SASL/PLAIN方式的不足而提供的另一种认证方式。这种方式的用户名/密码是存储中zookeeper的,因此能够支持动态添加用户。该种认证方式还会使用sha256或sha512对密码加密,安全性相对会高一些,在0.10.2版本引入;
三、部署配置
wget https://archive.apache.org/dist/kafka/3.4.0/kafka_2.13-3.4.0.tgz
tar -zxvf kafka_2.13-3.4.0.tgz -C /opt/
mv /opt/kafka_2.13-3.4.0. /opt/kafka
chown kafka:kafka -R /opt/kafka
cd /opt/kafka/
mkdir data
vim /opt/kafka/config/kraftserver.properties //如下所示# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller #the server acts as both a broker and a controller# The node id associated with this instance's roles
node.id=2# The connect string for the controller quorum 集群选举控制器配置,默认走 PLAINTEXT协议除非显示定义其他协议
controller.quorum.voters=1@172.18.1.176:9093,2@172.18.1.217:9093,3@172.18.1.150:9093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://172.31.7.237:9092,CONTROLLER://172.18.1.217:9093# Name of listener used for communication between brokers. it is used exclusively仅用于 for requests between brokers
inter.broker.listener.name=PLAINTEXT #注意与controller.listener.names不要冲突# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://172.18.1.217:9092#完成后,生成整个集群有一个唯一的ID标志,使用uuid。可使用官方提供的 kafka-storage 工具生成
/opt/kafka/bin/kafka-storage.sh random-uuid
或
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"#用上述ID格式化存储路径
/opt/kafka/bin/kafka-storage.sh format -t clust_ID -c /opt/kafka/config/kraft/server.properties
或
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
#完成后以kraft模式启动服务
bin/kafka-server-start.sh -daemon ./config/kraft/server.properties#创建topic
bin/kafka-topics.sh --create --topic First_Kafka_Topic --partitions 1 --replication-factor 3 --bootstrap-server 172.31.7.237:9092#查看
bin/kafka-topics.sh --list --bootstrap-server 172.31.7.237:9092

2)kafka启动脚本
#!/bin/bash
#kafka集群启动脚本
case $1 in"start"){for i in 172.18.1.176,172.18.1.217,@172.18.1.150doecho "--------启动 $i kafka with kraft-------"ssh $i "/home/kafka/bin/kafka-server-start.sh -daemon /home/kafka/config/kraft/server.properties"done
};;
"stop"){for i in 172.18.1.176,172.18.1.217,@172.18.1.150doecho "------停止 $i kafka--------"ssh $i "/home/kafka/bin/kafka-server-stop.sh"done
};;
esac
3)kafka kRaft SASL/PLAIN 安全认证配置 :
新建config 文件 config/kafka_server_jaas.conf,如下所示:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
serviceName="kafka"
username="admin"
password="admin"
user_admin="admin";
};
复制一份kafka-server-start.sh ,修改名称 kafka-server-start-sasl.sh启动脚本修改名称,引入加密文件:
……
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G -Djava.security.auth.login.config=/opt/kafka/kafka_2.13-3.4.0/config/kafka_server_jaas.conf"
fi
……
复制一份 server_sasl.properties 修改名称为server_sasl.properties 与非安全认证分开,编辑:
node.id=1
controller.quorum.voters=1@kraft1:9093
listeners=SASL_PLAINTEXT://172.31.7.237:9092,CONTROLLER:///172.18.1.217:9093
inter.broker.listener.name=SASL_PLAINTEXT
advertised.listeners=SASL_PLAINTEXT://172.31.7.237:9092
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
完成后启动kafka:sh ./bin/kafka-server-start-sasl.sh -daemon ./config/kraft/server_sasl.properties
四、附录:知识回顾
4.1、常用Message Queue对比
1)RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
2)Redis
Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。
3)ZeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用ZeroMQ程序库,可以使用NuGet安装,然后你就可以愉快的在应用程序之间发送消息了。但是ZeroMQ仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter的Storm 0.9.0以前的版本中默认使用ZeroMQ作为数据流的传输(Storm从0.9版本开始同时支持ZeroMQ和Netty作为传输模块)。
4)ActiveMQ
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。
5)Kafka/Jafka
Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。kafka3.0轻量级的单进程部署不仅可以替代ActiveMQ、RabbitMQ等传统的消息队列,同时也适合于边缘场景和使用轻量级硬件的场景。数据表明,一个可以管理 两百万分区的集群中,kafka3.0新版本中Quorum Controller的迁移过程可以 从几分钟缩小至30秒,突破了限制Kafka集群范围的元数据管理这个主要瓶颈,关机和重启 十多倍速于kafka2.8,性能完全实现了强力碾压!
4.2、Kafka的原理
Kafka的一种新的复制协议,它是在Kafka2.4版本中引入的。Kraft协议的目标是提高Kafka的可靠性和可维护性,满足分布式流处理需求;它主要包括以下几个方面:
1、去中心化:Kraft 协议将Kafka 的控制器节点去中心化,每个副本都可以成为控制器,从而提高了系统的可靠性和容错性。
2、原子性:Kraft 协议使用原子广播协议来保证消息的原子性,即所有副本都会收到相同的消息,从而保证了数据的一致性
3、可扩展性:Kraft 协议支持动态添加和删除副本,从而提高了系统的可扩展性和可维护性。
4、可靠性:Kraft 协议使用 Raft 算法来保证副本之间的一致性,从而提高了系统的可靠性和容错性。
4.3、DoctorKafka 管理工具
它是源于Pinterest产品的一个项目,为了扩展Kafka 服务的运维规模,Pinterest 构建了DoctorKafka,用于管理 Kafka 集群自愈和工作负载均衡;。DoctorKafka 能够探测到Kafka broker 的故障并自动将故障broker 的负载转移给健康的broker。现在,Pinterest 已经在 GitHub 上将该项目开源。DoctorKafka 由三部分组成,架构如下:

1、部署在每个 broker 上的指标收集器(metrics collector),它会定期收集 Kafka 进程和主机的指标,并将其发布到一个 Kafka 主题上。在这里,使用了 Kafka 作为 broker 的状态存储,这样的话,能够简化 DoctorKafka 的搭建过程并减少对其他系统的依赖;每个 broker 上都会运行一个指标收集器,它会收集 Kafka broker 输入和输出的网络流量指标以及每个副本(replica)的状态。
2、中心化的 DoctorKafka 服务会管理多个集群,分析 broker 的状态指标以探测 broker 的故障,执行集群自愈和负载均衡的命令。DoctorKafka 会将执行的命令记录在另外一个名为“Action Log”主题上;
3、用于浏览 Kafka 集群状态和执行流程的 Web UI 页面。
DoctorKafka 服务启动之后,它会首先读取 broker 最近 24 到 48 小时的状态,基于此,DoctorKafka 会推断每个副本工作负载所需的资源。因为 Kafka 工作负载主要是网络密集型的,DoctorKafka 主要关注副本的网络带宽使用情况。DoctorKafka 在启动之后,会阶段性地检查每个集群的状态。当探测到 broker 出现故障时,它会将故障 broker 的工作负载转移给有足够带宽的 broker。如果在集群中没有足够的资源进行重分配的话,它会发出告警。与之类似,当 DoctorKafka 进行工作负载平衡时,它会识别出网络流量超出配置的 broker,并将工作负载转移给流量更少的 broker,或者是执行更优的领导者选举(leader election)方案来转移流量。
DoctorKafka 已经在 Pinterest 运行了数月之久,并帮助其运维人员管理着 1000 个以上的集群。更多参见 项目地址。
4.4、Kafka WebUI之Kowl
Kowl ( Kafka Owl): Kafka WebUI for exploring messages, consumers. configurations and more with a focus on a good UI。更多参看:项目地址。
除上之外,还有9种常见的kafka UI工具,除此之外还有LogiKM 和 kafka-console-ui ,因Kafka-UI 功能齐全且免费,推荐。
1 AKHQ 免费
2 Kowl 部分收费
3 Kafdrop 免费
4 UI for Apache Kafka 免费
5 Lenses 免费
6 CMAK 免费
7 Confluent CC 收费
8 Conduktor 收费
9 LogiKM 免费
10 kafka-console-ui 免费

一般该程序通过docker容器运行,Kowl 的最大优势在于其出色的用户界面。它方便、用户友好且易于使用;启动后界面如下:
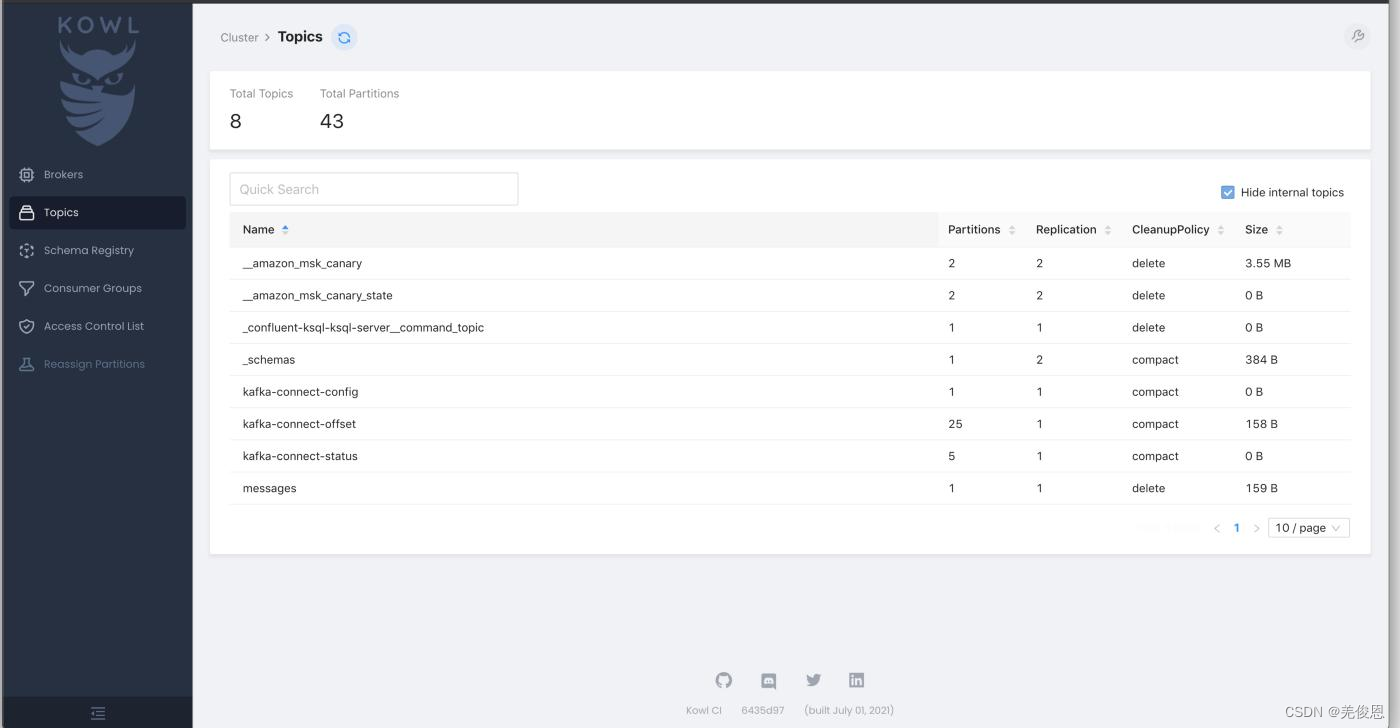
Kowl 提供消息浏览、实时跟踪以及对 Protobuf、Avro 和 Amazon MSK IAM 的支持,但登录系统(Google、GitHub、Okta)和具有组同步的 RBAC 权限仅适用于付费的 Kowl Business 计划。Kowl 还缺少多集群管理、动态主题配置、分区增加、副本更改、Kafka Connect 管理、模式注册表、KSQL 集成、Kafka Streams 拓扑、只读模式以及 JMX 指标的可视化和图表等功能。