深圳网站系统找哪里百度平台客服电话是多少
一.爬虫需求
- 获取对应所有专栏数据;
- 自动实现分页;
- 多线程爬取;
- 批量多账号爬取;
- 保存到mysql、csv(本案例以mysql为例);
- 保存数据时已存在就更新,无数据就添加;
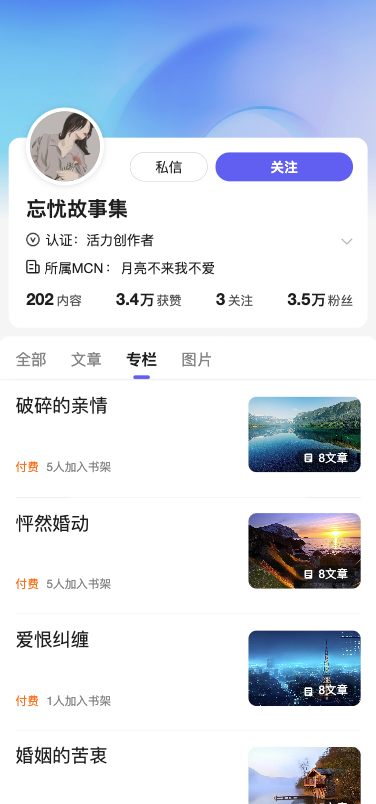
二.最终效果
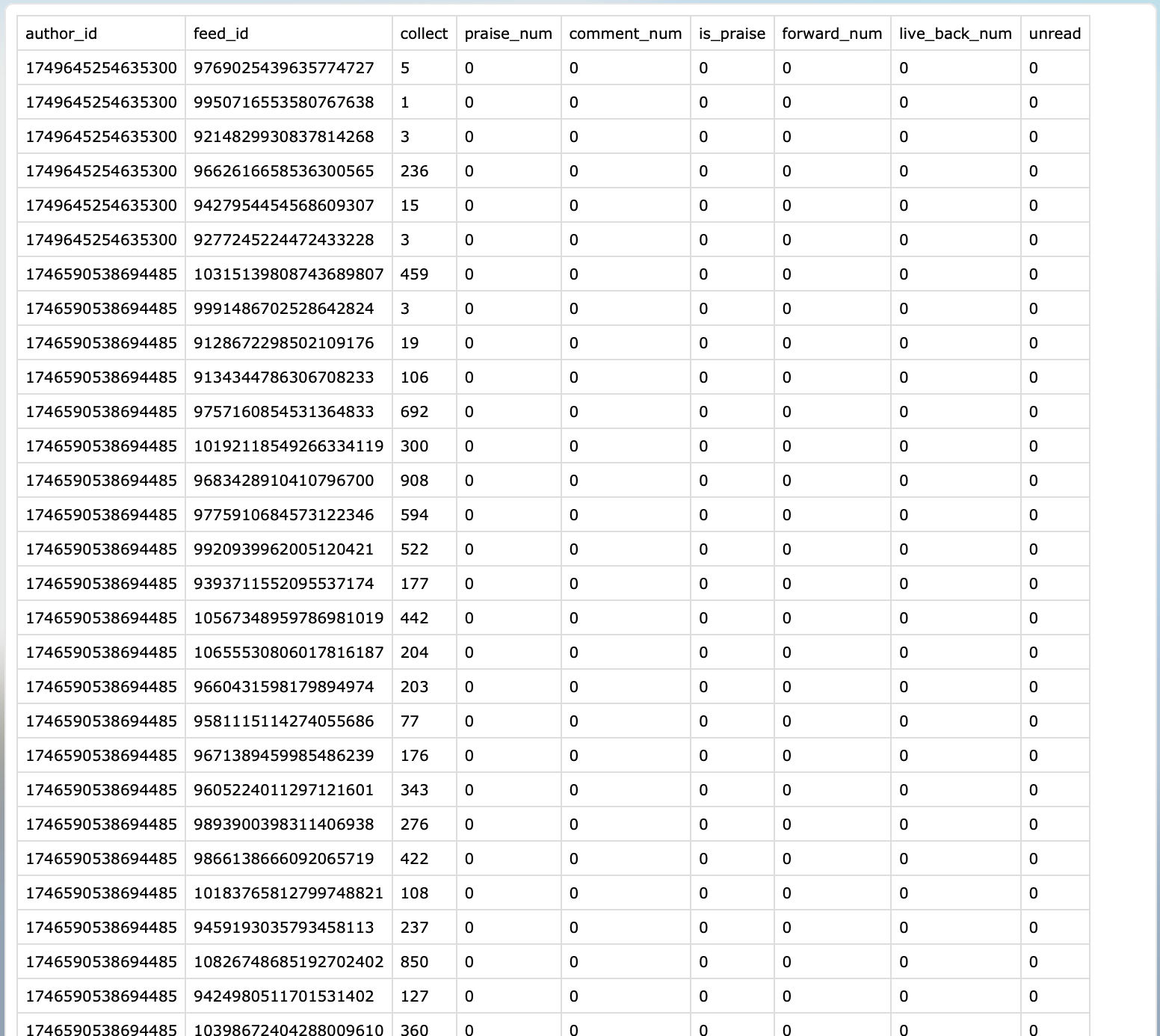
三.项目代码
3.1 新建项目
本文使用scrapy分布式、多线程爬虫框架编写的高性能爬虫,因此新建、运行scrapy项目3步骤:
1.新建项目:
scrapy startproject author
2.新建 spider:
scrapy genspider author "baidu.com"
3.运行 spider:
scrapy crawl authorSpider
注意:author 是spider中的name
4.编写item:
# Author专栏(xxx备注是预留未知对应字段)
class AuthorZhuanLanItem(scrapy.Item):# 专栏author_idauthor_id = scrapy.Field()# 专栏feed_idfeed_id = scrapy.Field()praise_num = scrapy.Field()comment_num = scrapy.Field()is_praise = scrapy.Field()forward_num = scrapy.Field()live_back_num = scrapy.Field()# 加入书架的人数collect = scrapy.Field()unread = scrapy.Field()5.编写爬虫解析代码:
# Author专栏数据
class AuthorItemPipeline(object):def open_spider(self, spider):if spider.name == 'author':# 插入数据sqlself.insert_sql = "INSERT INTO author(author_id,feed_id,praise_num,comment_num,is_praise,forward_num,live_back_num,collect,unread) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"# 更新数据sqlself.update_sql = "UPDATE author SET praise_num=%s,comment_num=%s,is_praise=%s,forward_num=%s,live_back_num=%s,collect=%s,unread=%s WHERE feed_id=%s"# 查询数据sqlself.query_sql = "SELECT * FROM author WHERE feed_id=%s"# 初始化数据库链接对象pool = PooledDB(pymysql,MYSQL['limit_count'],host=MYSQL["host"],user=MYSQL["username"],passwd=MYSQL["password"],db=MYSQL["database"],port=MYSQL["port"],charset=MYSQL["charset"],use_unicode=True)self.conn = pool.connection()self.cursor = self.conn.cursor()# 保存数据def process_item(self, item, spider):try:if spider.name == 'author':# 检查表中数据是否已经存在counts = self.cursor.execute(self.query_sql, (item['feed_id']))# counts大于0说明已经存在,使用更新sql,否则使用插入sqlif counts > 0:self.cursor.execute(self.update_sql,(...)else:self.cursor.execute(self.insert_sql,(...)...except BaseException as e:print("author错误在这里>>>>>>>>>>>>>", e, "<<<<<<<<<<<<<错误在这里")return itemimport re
import scrapy
from bs4 import BeautifulSoup as bs
from urllib.parse import urlencode
from baidu.settings import MAX_PAGE, author_headers, author_cookies
from ..items import AuthorZhuanLanItem
from baidu.Utils import Tooltool = Tool()
"""
爬虫功能:
用户-专栏-列表
"""class AuthorSpider(scrapy.Spider):name = 'author'allowed_domains = ['baidu.com']base_url = 'xxx'zhuanlan_url = "xxx"params = {...}headers = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}...四.运行过程

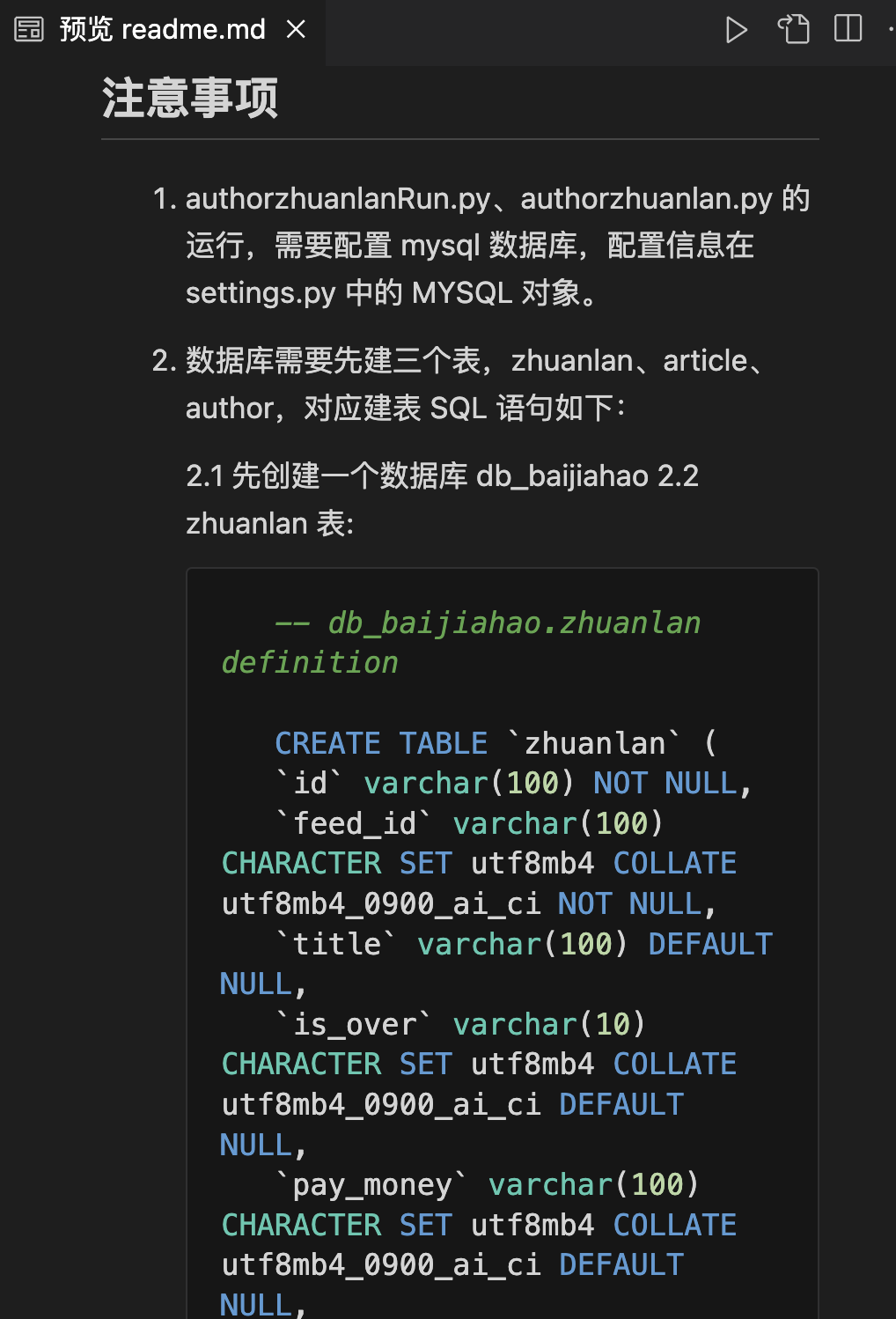
五.项目说明文档
六.获取完整源码
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复**“故事会”**即可获取。