空间设计大师电脑系统优化工具
RabbitMQ的exchange,即交换机有不同的类型:
1.direct Exchange(直接交换机)
匹配路由键,只有完全匹配消息才会被转发
2.Fanout Excange(扇出交换机)
将消息发送至所有的队列
3.Topic Exchange(主题交换机)
将路由按模式匹配,此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“abc.#”能够匹配到“abc.def.ghi”,但是“abc.*” 只会匹配到“abc.def”。
4.Header Exchange
在绑定Exchange和Queue的时候指定一组键值对,header为键,根据请求消息中携带的header进行路由
RabbitMQ六种工作模式
六种模式分别为Hello world、Work queues(工作队列)、Publish/Subscribe(发布订阅)、Routing(路由)、Topics(主题)、RPC(远程调用),除了RPC模式外,其余的模式都是从简单的使用到更为灵活的使用,基本的代码框架都是差不多的,只是在不同的模式下达到的效果不同,它们各有各的特点,在实际使用中应该根据需求来选择具体的模式,而不是简单粗暴的选择最“高端”的模式。
1. Hello world模式(也叫simple (简单模式))
Hello world模式是最简单的一种模式,一个producer发送message,另一个consumer接收message。

2. Work queues模式(工作模式)
Work queues模式即工作队列模式,也称为Task queues模式(任务队列模式),这个模式的特点在于,同一个queue可以允许多个consumer从中获取massage,RabbitMQ默认会从queue中依次循环的给不同的consumer发送message。一个生产者生产信息,多个消费者进行消费,但是一条消息只能消费一次

3. Publish/Subscribe模式(发布订阅模式)相当于广播
相对于工作/任务模式中的一个message只能发送给一个consumer使用,发布订阅模式会将一个message同时发送给多个consumer使用,其实就是producer将message广播给所有的consumer。
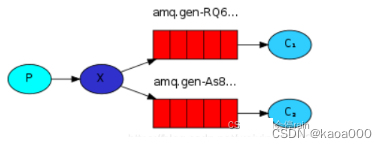
生产者首先投递消息到交换机,订阅了这个交换机的队列就会收到生产者投递的消息。
使用fanout交换机类型,传递到 exchange 的消息将会转发到所有与其绑定的 queue 上。
不需要指定 routing_key ,即使指定了也是无效。
需要提前将 exchange 和 queue 绑定,一个 exchange 可以绑定多个 queue,一个queue可以绑定多个exchange。
需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。如果不先启动订阅者,则发布者发布的消息订阅者是无法事后接收到的。
发布者:
import pika # 链接mq需要pika模块
import jsonuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储channel.exchange_declare(exchange='logs',exchange_type='fanout',)
for i in range(0,10):message = json.dumps({'消息ID':'1000%s'%i,},ensure_ascii=False)channel.basic_publish(exchange='logs',routing_key='',body=bytes(message,encoding='utf8'),)print(message)connection.close()接收者:
import pika
import jsonuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queue
print("temp queue name:",queue_name)
channel.queue_bind(exchange='logs',queue=queue_name,)def callback(ch, method, properties, body):print("[x] Received %r" % str(body,encoding='utf8'))# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认print('[*] Waiting for message. To exit press CTRL+C')# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()
4. Routing模式(路由模式),相当于组播
路由模式中,exchange类型为direct,与发布订阅模式相似,但是不同之处在于,发布订阅模式将message不加区分广播给所有的绑定queue,但是路由模式中,允许queue在绑定exchange时,同时指定 routing_key ,exchange就只会发送message到与 routing_key 匹配的queue中,其他的所有message都将被丢弃。当然,也允许多个queue指定相同的 routing_key ,此时效果就相当于fanout类型的发布订阅模式了。

生产者生产消息投递到direct交换机中,扇出交换机会根据消息携带的routing Key匹配相应的队列
生产者:
import pika # 链接mq需要pika模块
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='direct-logs',exchange_type='direct', # 类型为directdurable = True,)severity = sys.argv[1] if len(sys.argv)>1 else 'info' # 定义消息严重级别
message = ''.join(sys.argv[2:]) or 'Hello World!'channel.basic_publish(exchange='direct-logs',routing_key=severity, # 把消息发送到一组队列,这一组队列按routing_key分组body=message)
print(" [x] Sent %r:%r" % (severity,message))
connection.close()消费者:
import pika
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queueseverities = sys.argv[1:] # 可以输入多个级别
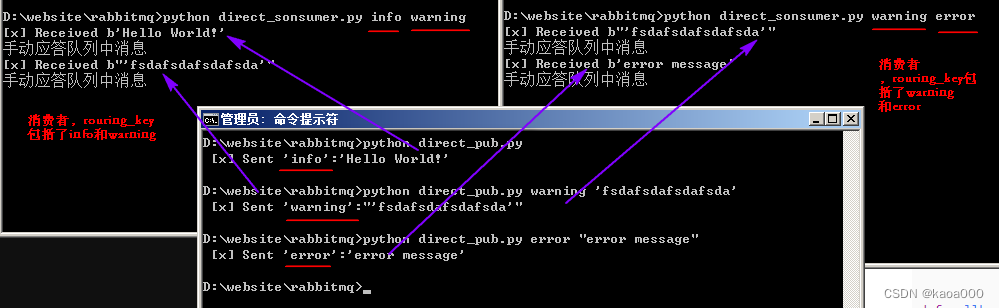
if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])sys.exit(1)for severity in severities: # 循环绑定routing_keychannel.queue_bind(exchange='direct-logs',queue=queue_name,routing_key=severity,)def callback(ch, method, properties, body):print("[x] Received %r" % body)# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认channel.start_consuming()运行结果:
5. Topics模式(主题模式)
主题模式的exchange类型为topic,相较于路由模式,主题模式更加灵活,区别就在于它的routing_key可以带通配符 * (匹配一个单词)和 # (匹配0个或多个单词),每个单词以点号分隔,但注意,routing_key的总大小不能超过255个字节。
如果一个message同时匹配了多个queue中的routing_key,那这几个queue都会收到这个message,如果一个message同时匹配了一个queue中的多个routing_key,那这个queue也只会接收一次这条message,如果一个message没有匹配上任何routing_key,那么这个message将被丢弃。
如果routing_key定义为 # (就只有这一个通配符),那么这个queue将接收所有message,就像exchange类型为fanout的发布订阅模式一样,如果routing_key两个通配符都没有使用,那么这个queue将会接收固定routing_key的message,就像exchange类型为direct的路由模式一样。
producer端:从代码上讲,producer的代码与路由模式没什么区别,只不过在routing_key的传值上需要注意与想要发送到的queue进行匹配。

生产者生产消息投递到topic交换机中,上面是完全匹配路由键,而主题模式是模糊匹配,只要有合适规则的路由就会投递给消费者。
生产者:
import pika # 链接mq需要pika模块
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='topic-logs',exchange_type='topic', # 类型为directdurable = True,)routing_key = sys.argv[1] if len(sys.argv)>1 else 'anonymous.info' # 定义消息严重级别message = ''.join(sys.argv[2:]) or 'Hello World!'channel.basic_publish(exchange='topic-logs',routing_key=routing_key, # 把消息发送到一组队列,这一组队列按routing_key分组body=message)
print(" [x] Sent %r:%r" % (routing_key,message))
connection.close()消费者:
import pika
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='topic-logs',exchange_type='topic',durable=True,)# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queuebinding_keys = sys.argv[1:] # 可以输入多个级别
if not binding_keys:sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])sys.exit(1)for binding_key in binding_keys: # 循环绑定routing_keychannel.queue_bind(exchange='topic-logs',queue=queue_name,routing_key=binding_key,)def callback(ch, method, properties, body):print("[x] Received %r" % body)# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认print('[*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()运行结果:可以使用*,#等进行过滤

6. RPC模式
RPC远程调用(Remote Procedure Call)模式其实就是使用消息队列处理请求的一种方式,通常请求接收到后会立即执行且多个请求是并行执行的,如果一次性来了太多请求,达到了服务端处理请求的瓶颈就会影响性能,但是如果使用消息队列的方式,最大的一点好处是可以不用立即处理请求,而是将请求放入消息队列,服务端只需要根据自己的状态从消息队列中获取并处理请求即可。
producer端:RPC模式的客户端(producer)需要使用到两个queue,一个用于发送request消息(此queue通常在服务端声明和创建),一个用于接收response消息。另外需要特别注意的一点是,需要为每个request消息指定一个uuid(correlation_id属性,类似请求id),用于识别返回的response消息是否属于对应的request。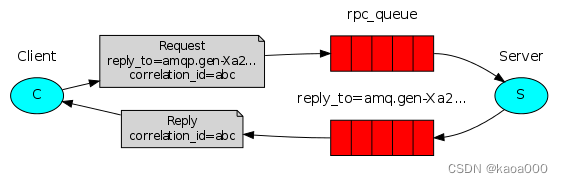
客户端client:
import pika
import uuidclass FibonacciRpcClient(object):def __init__(self):self.connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117', 5672, '/', pika.PlainCredentials('tester','test1234')))self.channel = self.connection.channel()result = self.channel.queue_declare('',exclusive=True) # 随机生成一个临时的唯一的queueself.callback_queue = result.method.queue # 这个临时唯一queue的名字# 注意,这个临时queue不是用于发送消息的,是用于接收消息的,这个queue名字,# 会传给server端,server端用这个Queue发送消息,也就是客户端指定了服务器端要使用的queueself.channel.basic_consume(on_message_callback=self.on_response,auto_ack=False,queue=self.callback_queue,) # 这是客户端发送完请求后,接收服务器端返回消息的配置,注意queue就是上面生成的临时queuedef on_response(self,ch,method,props,body):if self.corr_id == props.correlation_id:self.response = bodych.basic_ack(delivery_tag=method.delivery_tag)print("手动应答成功")def call(self,n):self.response = Noneself.corr_id = str(uuid.uuid4())self.channel.basic_publish(exchange='',routing_key='rpc_queue',properties=pika.BasicProperties(reply_to=self.callback_queue,correlation_id=self.corr_id,# 这个参数是用来标识本次请求,如果客户端发送多个请求,每个请求有不同的uuid,以此进行区分,类似cookie),body=str(n))while self.response is None:self.connection.process_data_events() # 以非阻塞的方式去检查有没有新消息,return int(self.response)fibonacci_rpc = FibonacciRpcClient()print("[x] Requesting fib(7)")
response = fibonacci_rpc.call(7)
print("[.] Got %r" % response)服务器端server:
import pikauser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info,))channel = connection.channel()channel.queue_declare(queue='rpc_queue')def fib(n):if n == 0:return 0elif n == 1:return 1else:return fib(n-1) + fib(n-2)def on_request(ch,method,props,body):n = int(body)print("[.] fib(%s)" % n)response = fib(n)ch.basic_publish(exchange='',routing_key=props.reply_to,properties=pika.BasicProperties(correlation_id=props.correlation_id),body=str(response))ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_message_callback=on_request, queue='rpc_queue')print("[x] Awaiting RPC requests")
channel.start_consuming()要注意的是,作为RPC模式,client端一开始是消息发送方,即发布者,server端是消费者,当server端收到消息后,经过处理,要将处理结果再返回给client端,此时,server端就是发布者,client端就是消费者,并且server端发布时使用的queue是client端指定的,即client端生成的临时queue。
correlation_id主要是为了在异步处理中,客户端发送多个请求,服务器端返回的响应因处理速度不同,可能响应的顺序也不同,为了区分不同的请求的响应,使用此标志。