西安哪家网站建设好百度首页推广广告怎么做
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
点击传送:大数据学习专栏
持续更新中,感谢各位前辈朋友们支持学习~
文章目录
- 1.Spark on Yarn集群模式介绍
- 2.搭建环境准备
- 3.搭建步骤
1.Spark on Yarn集群模式介绍
Apache Spark是一个快速的、通用的大数据处理框架,它支持在各种环境中进行分布式数据处理和分析。在Yarn集群模式下搭建Spark环境可以充分利用Hadoop的资源管理和调度能力。
本文将介绍如何搭建Spark on Yarn集群模式环境,步骤详细,代码量大,准备发车~

2.搭建环境准备
本次用到的环境有:
Java 1.8.0_191
Spark-2.2.0-bin-hadoop2.7
Hadoop 2.7.4
Oracle Linux 7.4
3.搭建步骤
1.解压Spark压缩文件至/opt目录下
tar -zxvf ~/experiment/file/spark-2.2.0-bin-hadoop2.7.tgz -C /opt

2.修改解压后为文件名为spark
mv /opt/spark-2.2.0-bin-hadoop2.7 /opt/spark

3.复制spark配置文件,首先在主节点(Master)上,进入Spark安装目录下的配置文件目录{ $SPARK_HOME/conf },并复制spark-env.sh配置文件:
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh

4.Vim编辑器打开spark配置文件
vim spark-env.sh
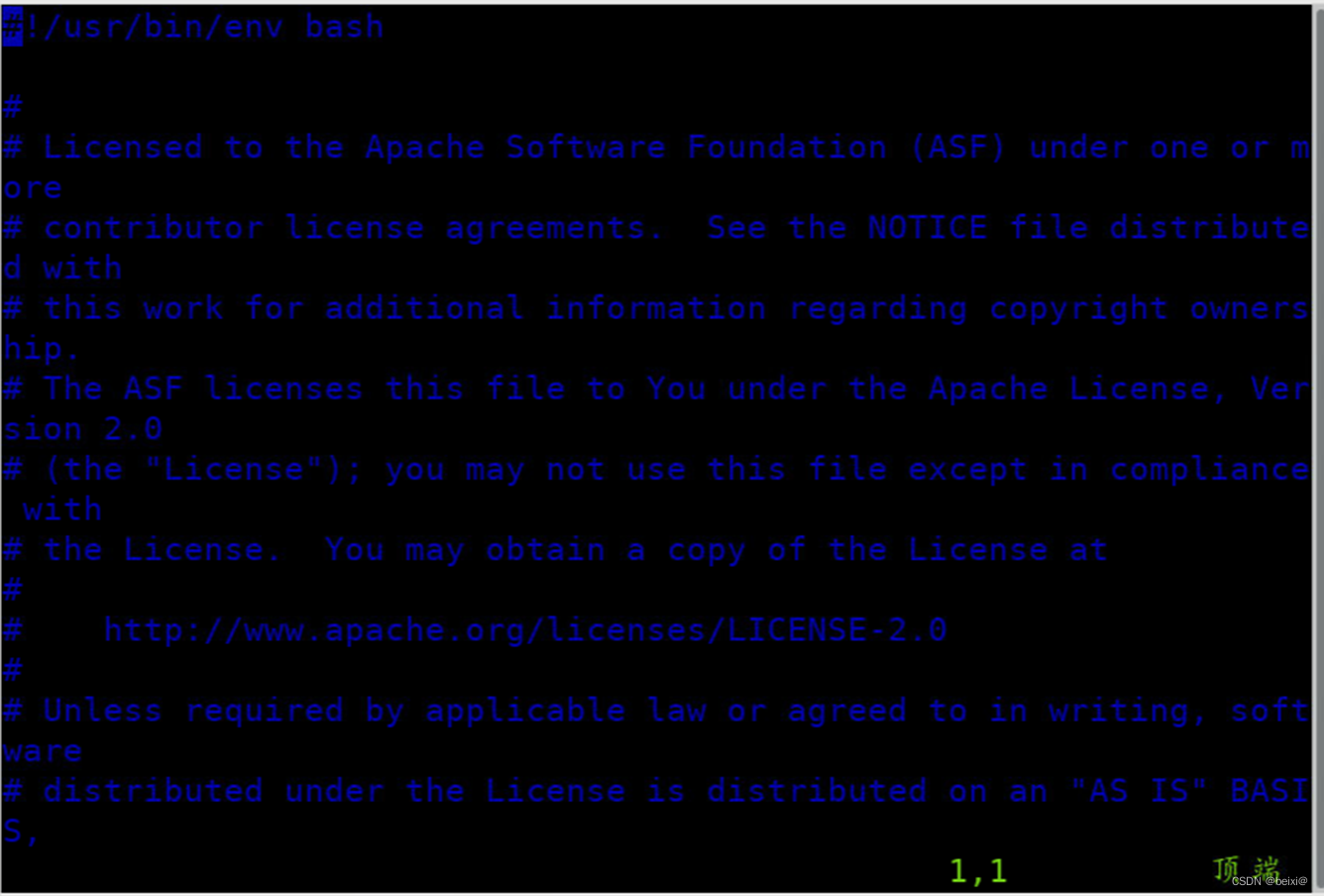
5.按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码,注意:“=”附近无空格:
export JAVA_HOME=/usr/lib/java-1.8
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
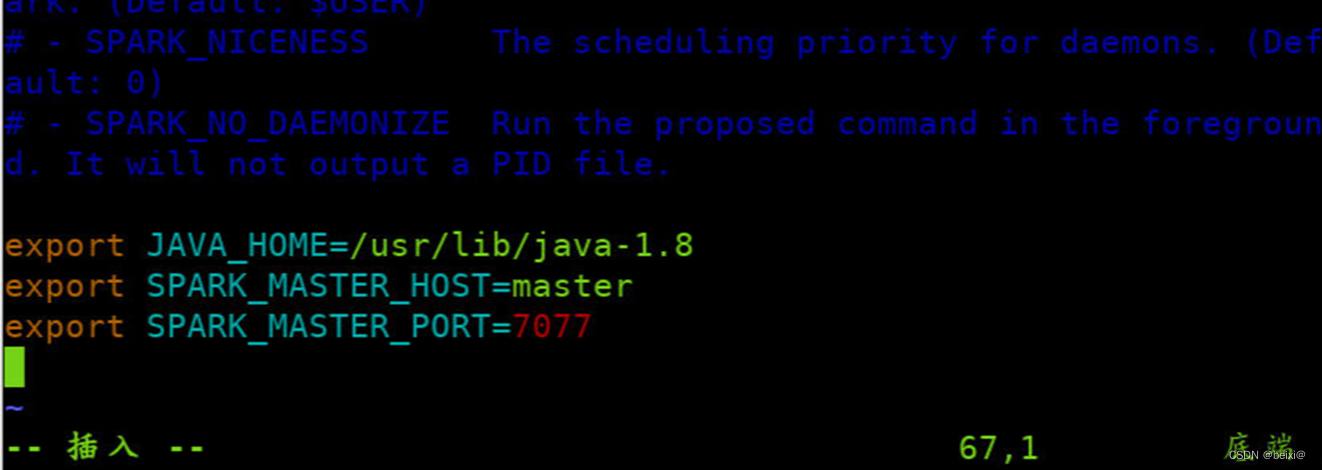
6.复制一份spark的slaves配置文件
cp slaves.template slaves

7.修改spark的slaves配置文件
vim slaves

8.每一行添加工作节点(Worker)名称,按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
slave1
slave2
按键Esc,按键:wq保存退出
9.复制spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf

10.通过远程scp指令将Master主节点的Spark安装包分发至各个从节点,即slave1和slave2节点
scp -r /opt/spark/ root@slave1:/opt/
scp -r /opt/spark/ root@slave2:/opt/


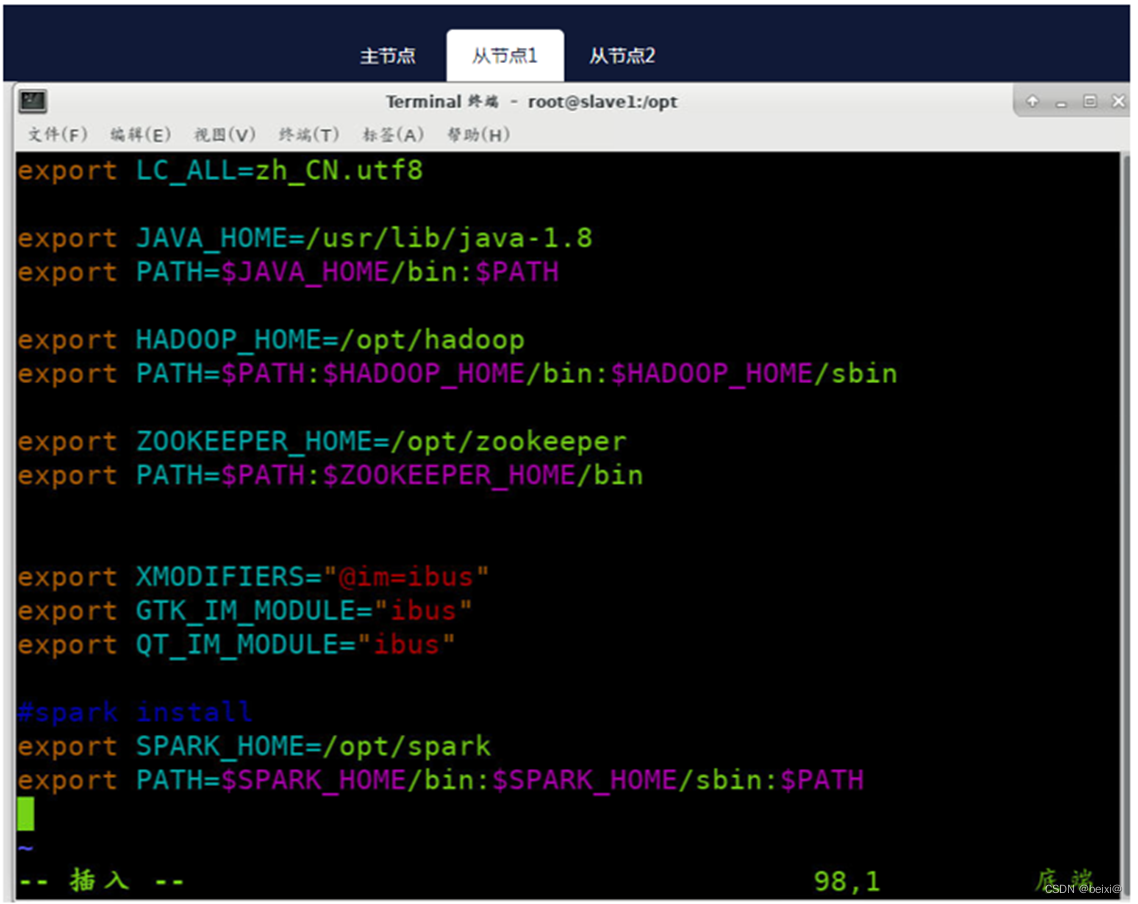
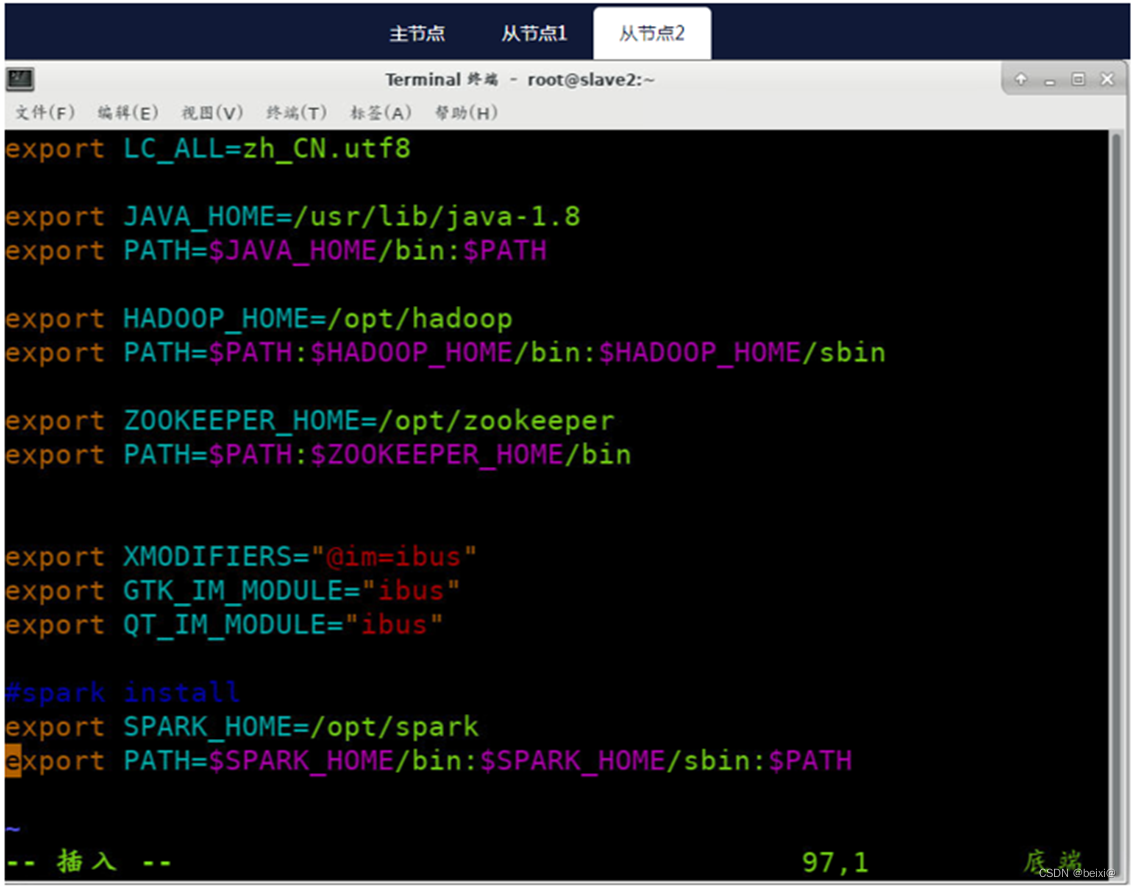
11.配置环境变量:分别在master,slave1和slave2节点上配置环境变量,修改【/etc/profile】,在文件尾部追加以下内容
vim /etc/profile
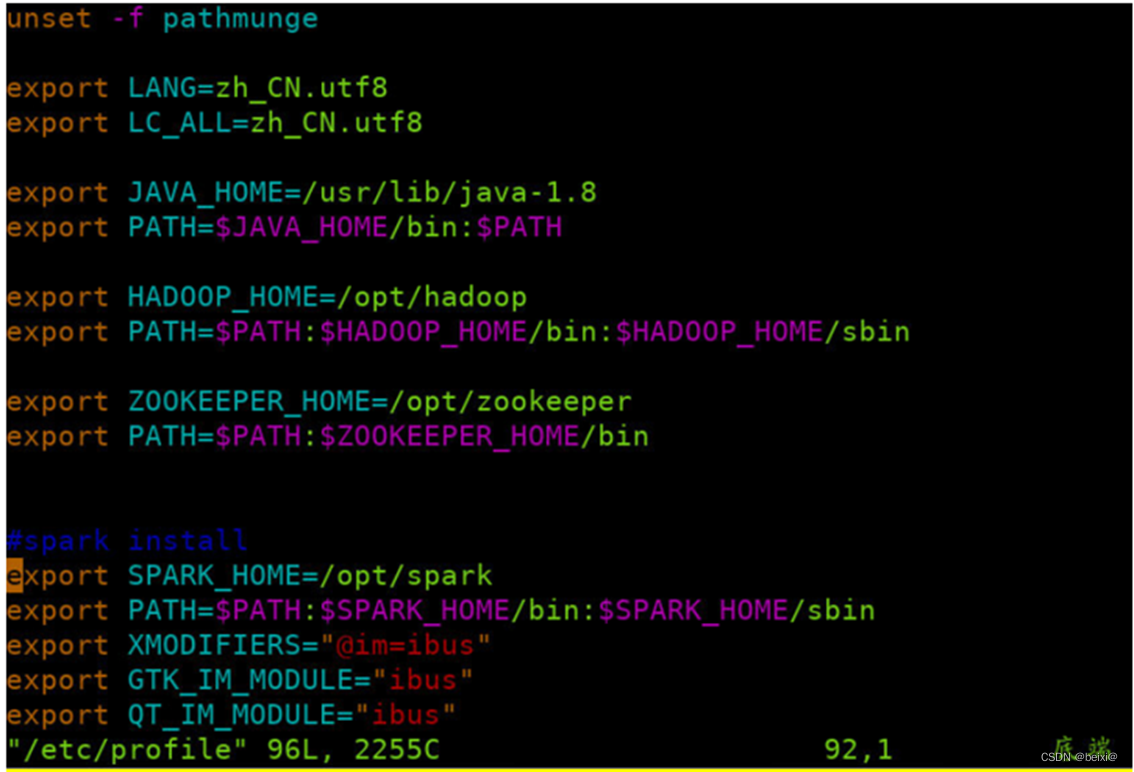
按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
#spark install
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
主节点(master)上执行截图,如下:

从节点1(Slave1)上执行截图,如下:
从节点2(Slave2)上执行截图,如下:

12.按键Esc,按键:wq保存退出
13.分别在Slave1和Slave2上,刷新配置文件
source /etc/profile

14.绑定Hadoop配置目录(在主节点),Spark搭建On YARN模式,只需修改spark-env.sh配置文件的HADOOP_CONF_DIR属性,指向Hadoop安装目录中配置文件目录,具体操作如下
vim /opt/spark/conf/spark-env.sh
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
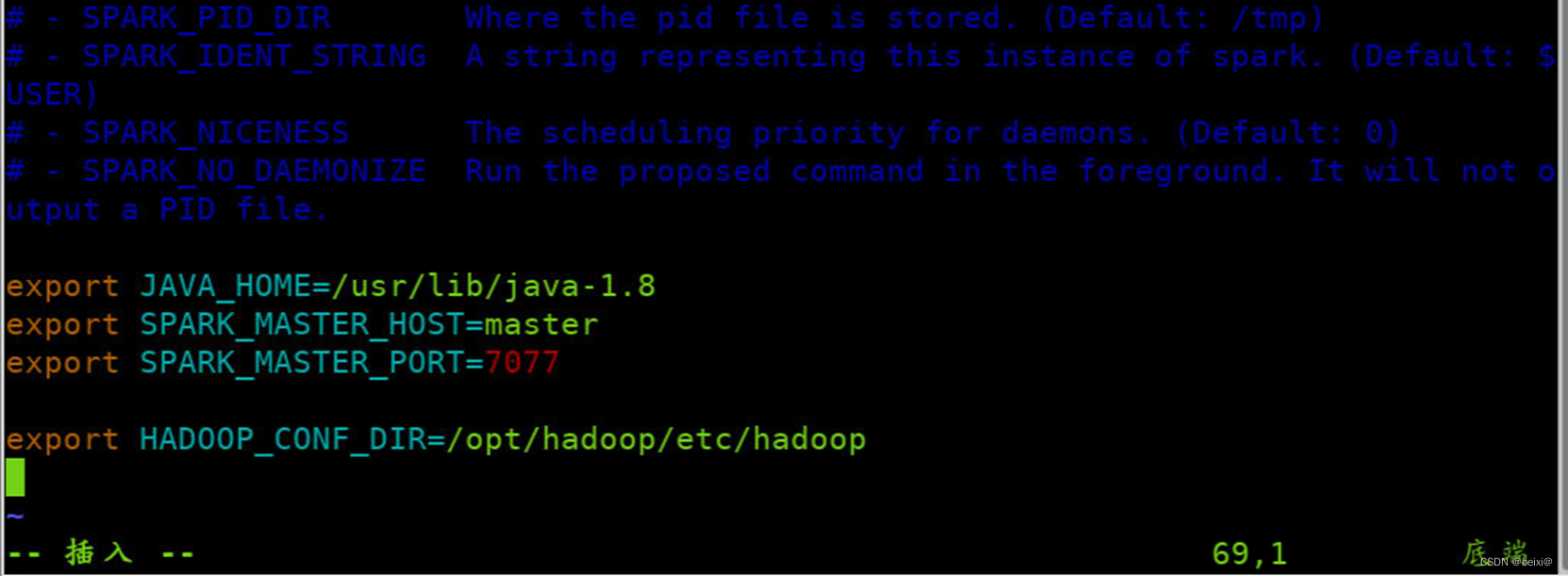
15.按键Esc,按键:wq保存退出
16.在主节点修改完配置文件后,一定要将【/opt/spark/conf/spark-env.sh】文件同步分发至所有从节点,命令如下
scp -r /opt/spark/conf/spark-env.sh root@slave1:/opt/spark/conf/
scp -r /opt/spark/conf/spark-env.sh root@slave2:/opt/spark/conf/

17.注意事项,如不修改此项,可能在提交作业时抛相关异常,Yarn的资源调用超出上限,需修在文件最后添加属性改默认校验属性,修改文件为
{HADOOP_HOME/etc/hadoop}/yarn-site.xml
vim /opt/hadoop/etc/hadoop/yarn-site.xml
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
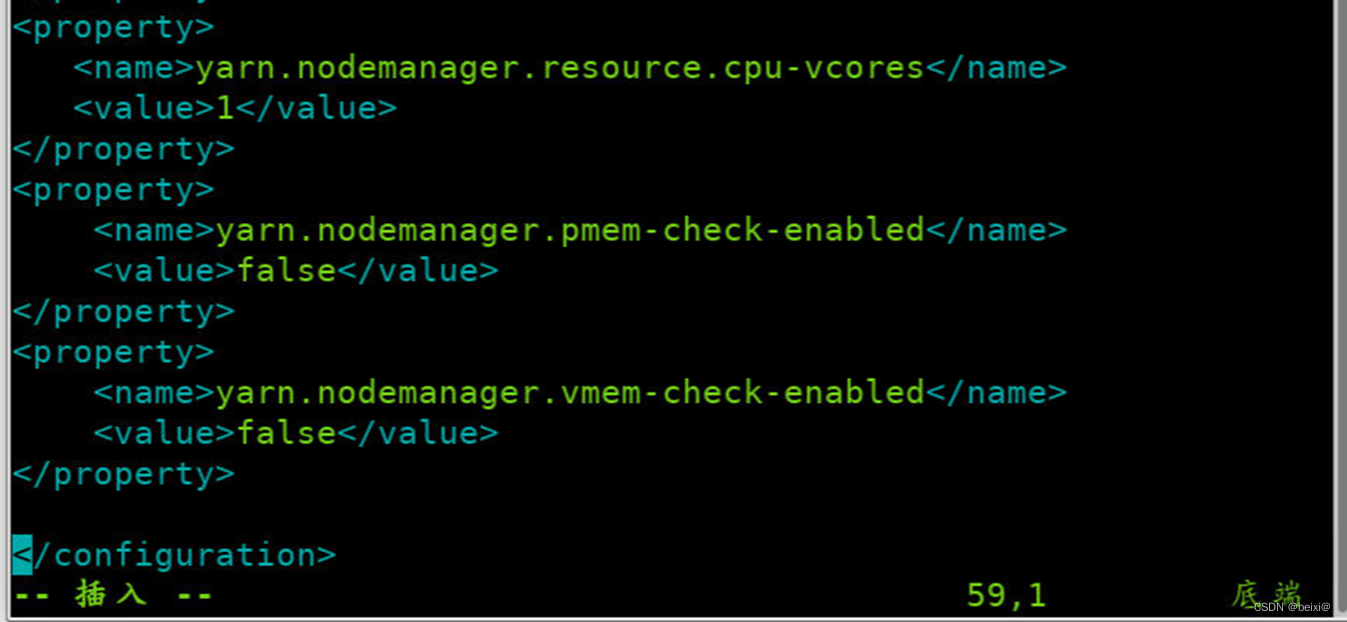
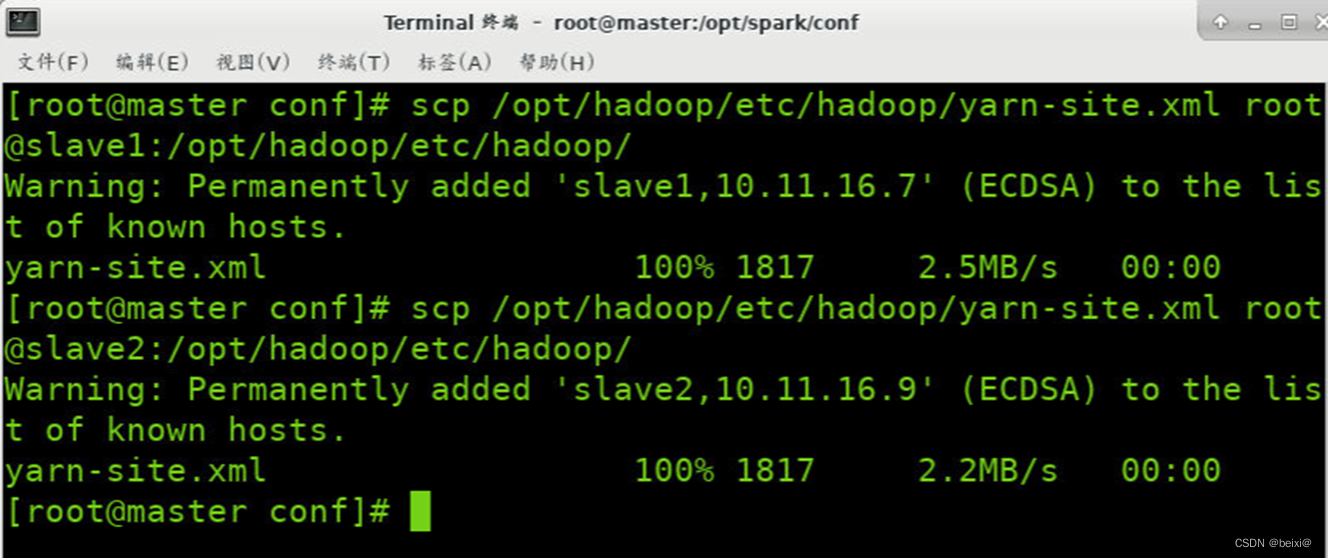
18.修改完成后分发至集群其它节点:
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@slave1:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@slave2:/opt/hadoop/etc/hadoop/
19.开启Hadoop集群,在开启Spark On Yarn集群之前必须首先开启Hadoop集群,指令如下:
start-dfs.sh
start-yarn.sh

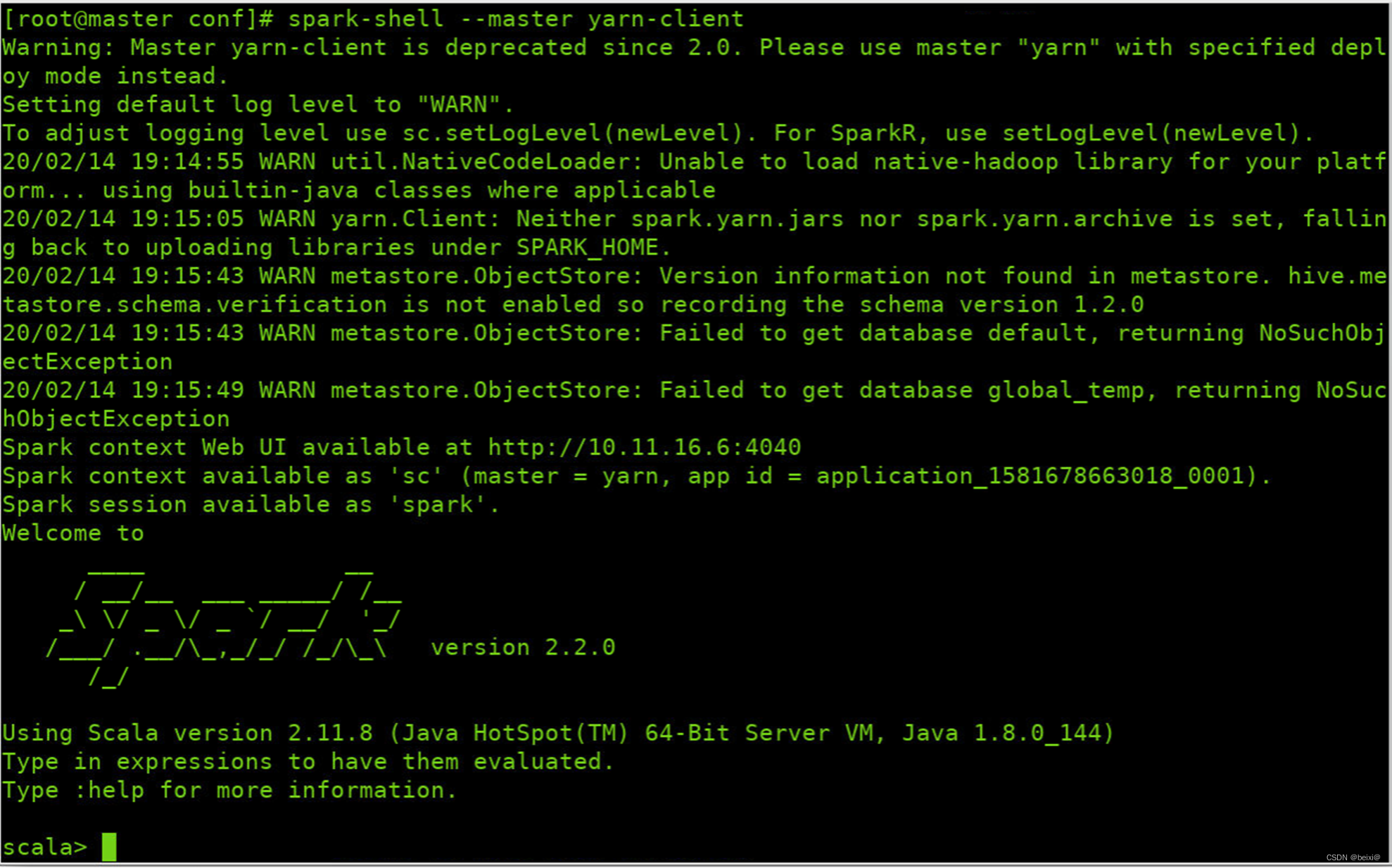
20.开启spark shell会话
spark-shell --master yarn-client
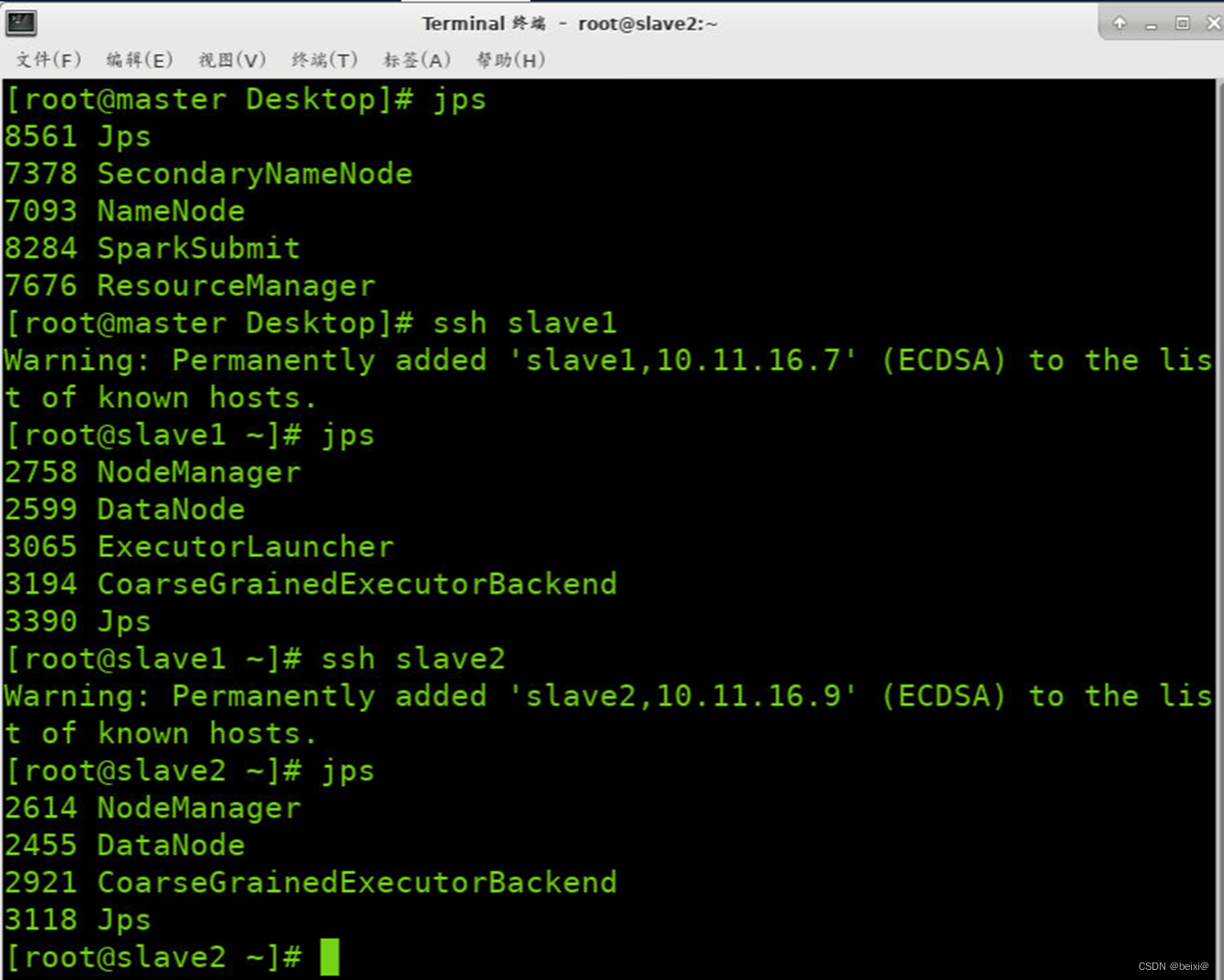
21.查看三台节点的后台守护进程
jps
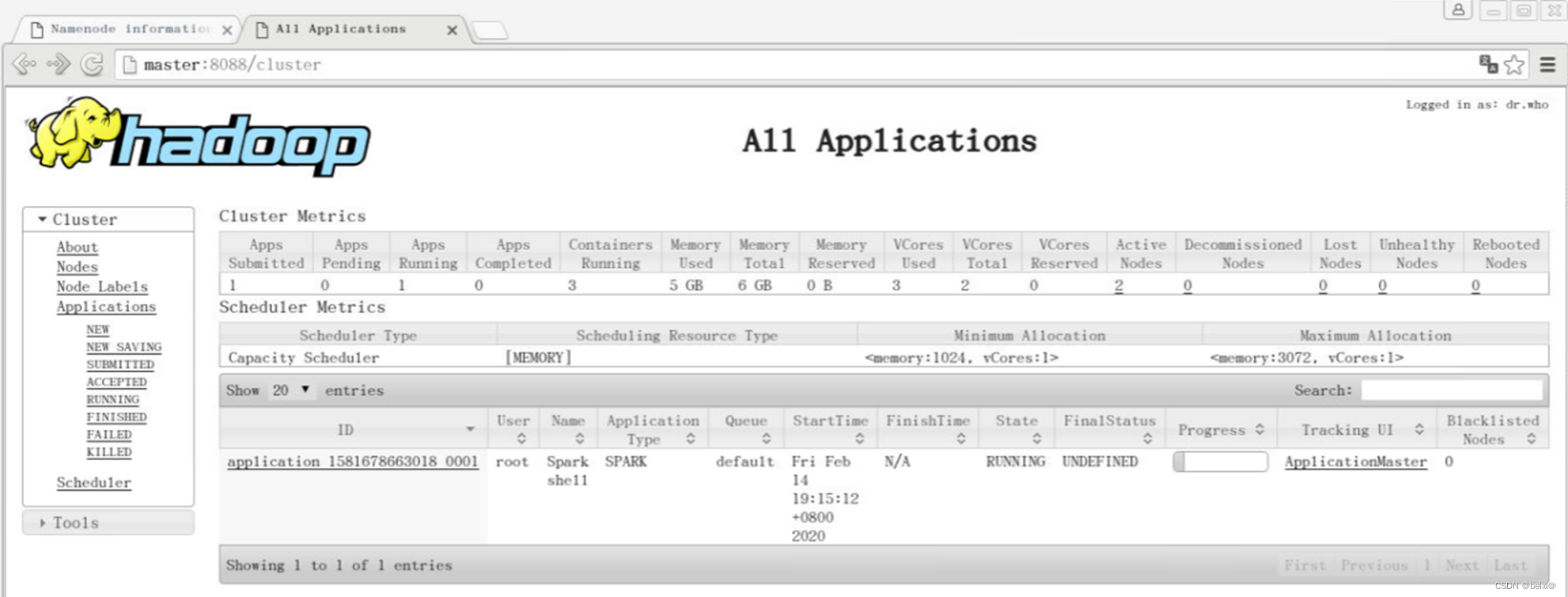
22.查看查看WebUI界面,应用提交后,进入Hadoop的Yarn资源调度页面http://master:8088,查看应用的运行情况,如图所示
所有配置完成,如果本篇文章对你有帮助,记得点赞关注+收藏哦~