深圳开发网站开发正规推广平台
Towards Real World Blind Face Restoration with Generative Facial Prior
这个projec相对codeformer已经是老一些的了,CodeFormer paper说自己的效果比这个更好。
有看了这个视频,它借用了R-ESRGAN 4x 和 GFPGAN 50%,既保留了一些人物特征,又有了更好的效果。视频例子
传统方式
Blind Face Restoration:
- 基于脸部固定位置的信息:没有充分挖掘信息,缺少细节,但是对于一个粗略的脸部信息是OK的
- heavily 基于reference
images: 对于政府需要的强制性信息来说这个应该不难获取(比如犯过刑事案件同志的档案),但是对于其它情况,这个有点不切实际。
例子:包含适用普通GAN的
Modules
Degradation Removal:(Unet)
将不好的,有影响画质的内容去除
不同尺寸的feature 会被输出
Pre-trained Face GAN (StyleGAN2)
补充好的,丰富的面部信息
借用之前的spatial feature,得到画质更好的features
Losses
- Reconstruction loss
- Adversarial loss
- Facial component Loss with local discriminators
- Identity Preserving loss
Codeformer
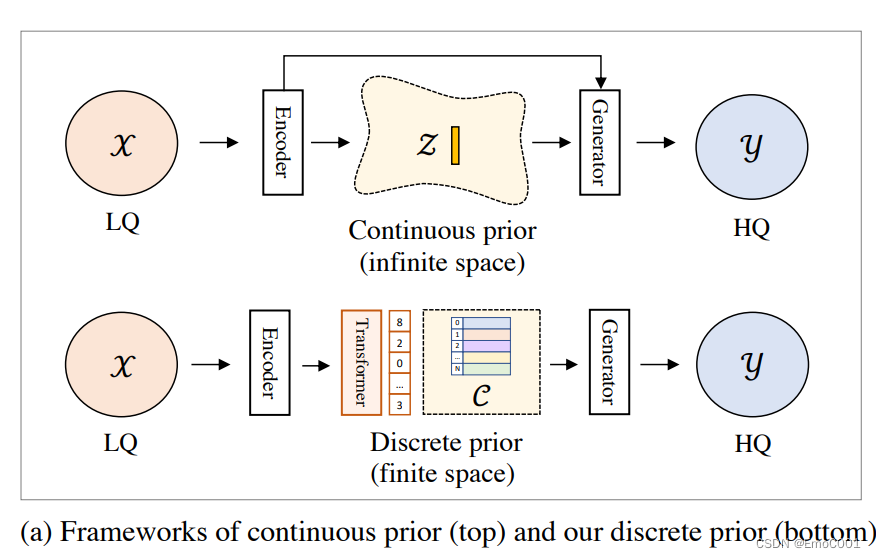
亮点:
- 直接用高清后的图片做训练
- Codebook 替代了之前包含不确定性的连续的且无线空间,现在是有限的离散空间。离散编码参考了VQ-VAE (包含向量量化)。VAE 通常套路中间的latent是连续的,但是现在是codebook。
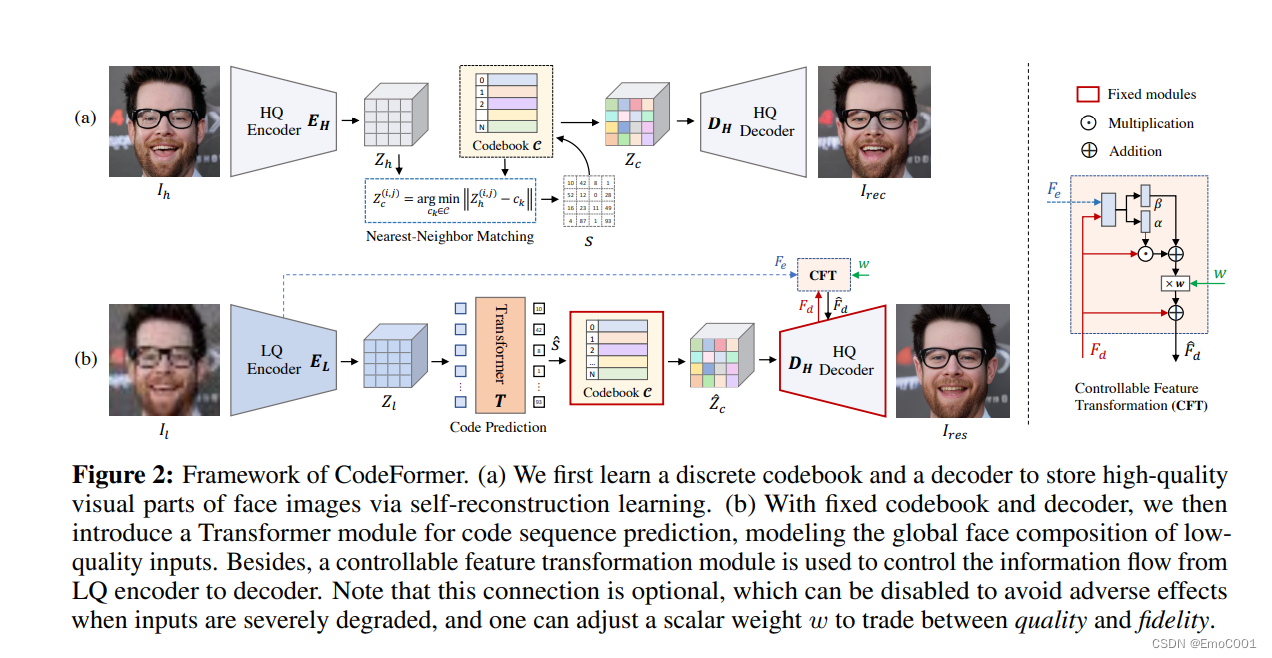
好的,接下来,他们要开始提升了,加入了transformer,这个也是应该看透了transformer的有点,有点类似于特征整理器。经过这里后的信息会分门别类的输出出来,这样能够有得到更有用的特征给Decoder生成更棒的图片。
整个过程,个人感觉也是借鉴了GFPGAN : Degradation Removal:(Unet),Pre-trained Face GAN (StyleGAN2) 分别替换成了 (a) 和 (b), 相当于我一开始不优化图片了,直接学一个Remover后的优化图片。然后做真正的图的输出,这里使用了transformer出来的内容,代替了GFPGAN里从前一轮unet获得的不同尺寸的features。从稍微混的feature 到一个特征区分更明显的feature。(自己理解是这样的,可能也只是因为先看的GFPGAN paper,会觉得类似)