加强政府信息公开和网站建设如何利用网络进行推广和宣传
模式识别 —— 第二章 参数估计
文章目录
- 模式识别 —— 第二章 参数估计
- 最大似然估计(MLE)
- 最大后验概率估计(MAP)
- 贝叶斯估计
最大似然估计(MLE)
在语言上:
- 似然(likelihood)和**概率(probability)**是同义词,都指事件发生的可能性。
但是在统计中:
- 概率是已知参数,对结果可能性的预测。
- 似然是已知结果,对参数是某个值的可能性预测。
可见这两个过程正好是相反的。
因此最大似然估计是已知数据来求概率最大的参数。
以抛硬币为例,假设我们有一枚硬币,现在要估计其正面朝上的概率θ\thetaθ。我们进行了10次实验其中正面朝上的次数为6次,反面朝上的次数为4次。
对一个独立同分布的样本集来说,总体的似然就是每个样本似然的乘积。针对抛硬币的问题,似然函数可写作:
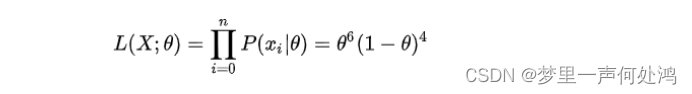
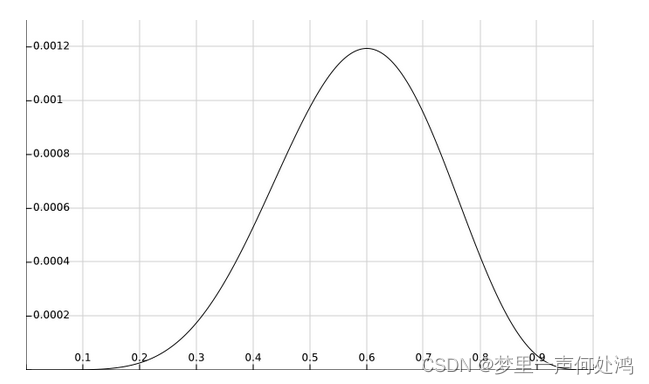
似然函数图如下:
由于总体的似然就是每个样本似然的乘积,为了求解方便,我们通常会将似然函数转成对数似然函数,然后再求解。可以转成对数似然函数的主要原因是对数函数并不影响函数的凹凸性。因此上式可变为:
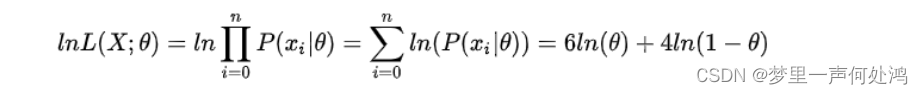
对该式子求导等于0即可解出当θ^=0.6\hat{\theta} = 0.6θ^=0.6时,是最优参数。
正态分布的最大似然估计
假设样本服从正态分布NNN~(μ,σ2)(\mu,\sigma^2)(μ,σ2),则其似然函数为:
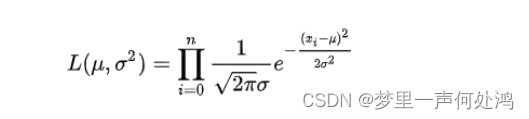
对其取对数得:
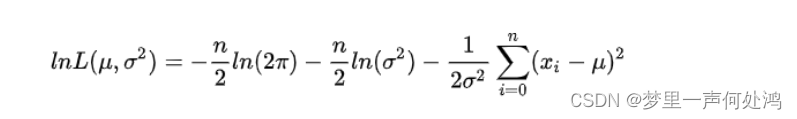 分别对μ,σ2\mu , \sigma^2μ,σ2求偏导,并令偏导数为0,得:
分别对μ,σ2\mu , \sigma^2μ,σ2求偏导,并令偏导数为0,得:
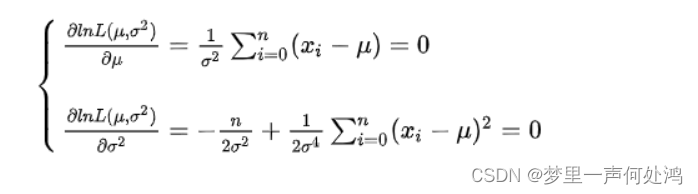
解得:
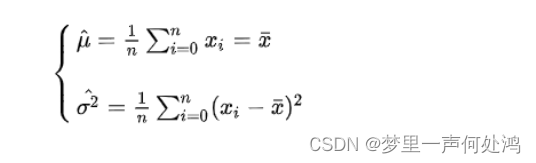
最大似然估计的求解步骤:\red{最大似然估计的求解步骤:}最大似然估计的求解步骤:
- 确定似然函数
- 将似然函数转化为对数似然函数
- 求对数似然函数的最大值(求导,解似然方程)
最大后验概率估计(MAP)
最大似然估计认为使似然函数P(X∣θ)P(X\mid \theta)P(X∣θ)最大的θ\thetaθ就是最好的参数θ\thetaθ。此时最大似然估计是将θ\thetaθ看作固定的值,只是其值未知。
最大后验概率认为θ\thetaθ是一个随机变量θ\thetaθ,即具有某种概率分布,称为先验分布,求解时除了要考虑似然函数P(X∣θ)P(X\mid \theta)P(X∣θ)之外还要考虑θ\thetaθ的先验分布P(θ)P( \theta)P(θ)。其认为P(X∣θ)P(θ)P(X\mid \theta)P( \theta)P(X∣θ)P(θ)取最大时的θ\thetaθ才是最优参数。
由于XXX的先验分布P(X)P( X)P(X)是固定的,所以其不影响对参数θ\thetaθ的判断。因此最大后验概率估计的公式表示为:
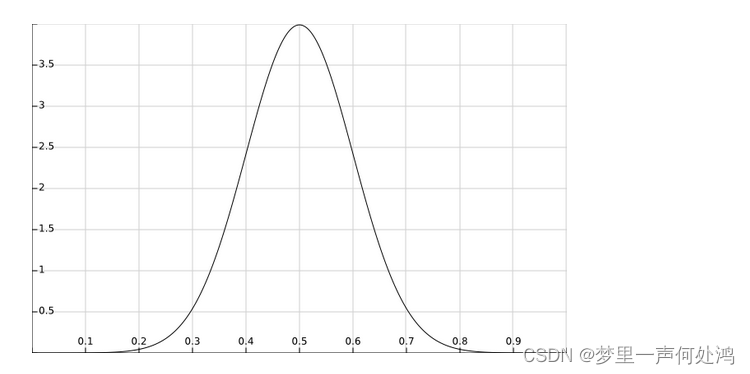
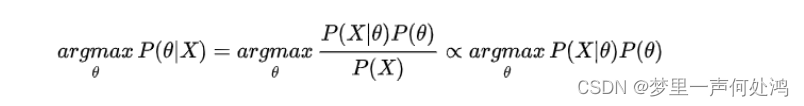 在抛硬币的例子中,通常认为当θ=0.5\theta = 0.5θ=0.5时可能性最大。因此我们用均值为0.5,方差为0.1的高斯分布来描述θ\thetaθ的先验概率分布。其表达式如下:
在抛硬币的例子中,通常认为当θ=0.5\theta = 0.5θ=0.5时可能性最大。因此我们用均值为0.5,方差为0.1的高斯分布来描述θ\thetaθ的先验概率分布。其表达式如下:
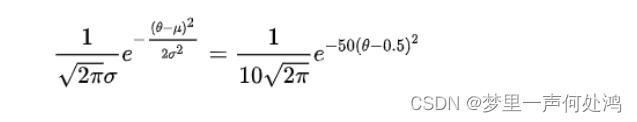
先验分布的函数如图:
因此,先验与似然的乘积如下:
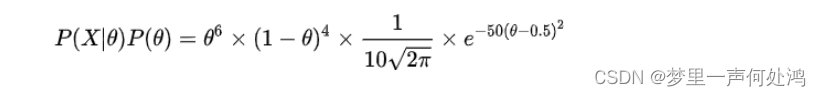 为了方便求导,我们将其转化为对数函数:
为了方便求导,我们将其转化为对数函数:
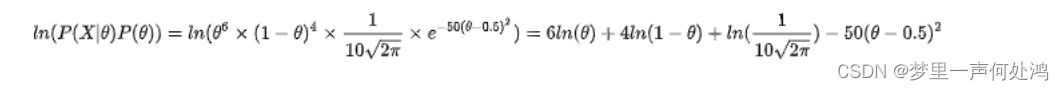
让上式为0化简得:
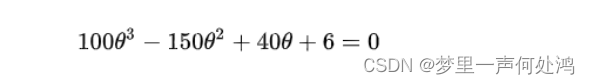
解得,θ^≈0.529\hat{\theta} \approx 0.529θ^≈0.529
相比最大似然估计的θ^=0.6\hat{\theta} = 0.6θ^=0.6,可见在最大后验概率估计中θ\thetaθ的估计值与θ\thetaθ的先验分布有的很大的关系。
最大后验概率估计的求解步骤:\red{最大后验概率估计的求解步骤:}最大后验概率估计的求解步骤:
- 确定参数的先验分布以及似然函数
- 将其乘积转换为对数形式
- 求对数函数的最大值(求导,解方程)