专门做旅游的视频网站有哪些谷歌推广平台
本文记录了从环境部署到微调模型、效果测试的全过程,以及遇到几个常见问题的解决办法,亲测可用(The installed version of bitsandbytes was compiled without GPU support. NotImplementedError: Architecture ‘LlamaForCausalLM’ not supported!,RuntimeError: Internal: could not parse ModelProto from E:\my\ai\llama3\models\my-llama-3-8b-0517\tokenizer.json)
一 安装开发环境
1 创建环境
首先请确报你已经安装好了conda工具
在命令行中键入如下指令创建python环境
conda create -n llama_factorypython=3.10 -y
创建成功后切换到新环境
conda activate llama_factory
安装cuda pytorch等核心工具
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 -c pytorch -c nvidia
pip3 install torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install llmtuner
2 下载可微调的模型
- 创建用于存放模型的文件夹,取名为models
- 将llama3 8b的模型文件项目下载到此处。下载时间稍微有点长,请耐心等待
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
3 安装llama factory
- 回到上层目录,将llama factory源代码拉到此处
git clone https://github.com/hiyouga/LLaMA-Factory.git - 完成后进入项目目录,
cd LLaMA-Factory - 安装环境依赖
pip install -e .[metrics,modelscope,qwen]
pip install -r requirements.txt --index-url https://mirrors.huaweicloud.com/repository/pypi/simple
4 运行llama factory
- 回到上层目录,修改下面的代码,将刚才下载的模型目录替换进来,然后把这一堆代码复制后,在命令行中敲入
python src/web_demo.py
–model_name_or_path E:\my\ai\llama3\models\Meta-Llama-3-8B-Instruct(模型目录)
–template llama3
–infer_backend vllm
–vllm_enforce_eager - 如果看到下面这个图就说明成功了。复制里面的端口号组成地址:localhost:7860,复制到浏览器打开

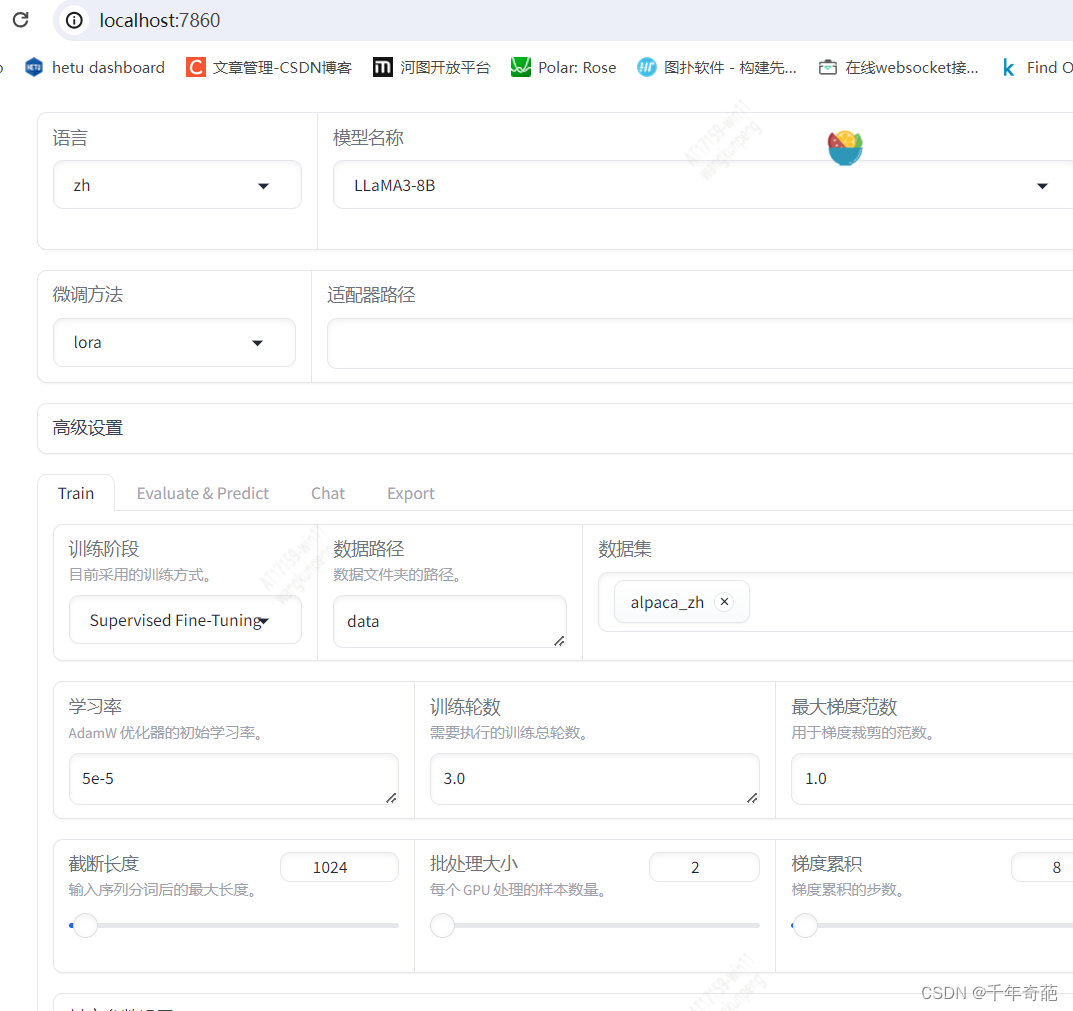
成功打开训练页面。
如果运行失败,提示The installed version of bitsandbytes was compiled without GPU support.,那说明你的环境出现了问题。请查看这篇文章解决The installed version of bitsandbytes was compiled without GPU support ,亲测可用
二 数据微调
1 制作训练数据
进入llama-factory/data目录
新建一个json文件起名为my_data_zh.json
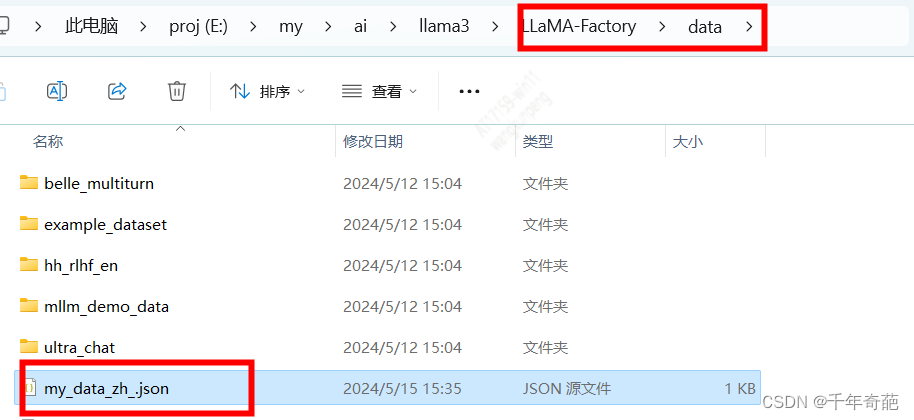
按下面的格式填入你的训练数据后保存即可,条数不限哦
数据集参数说明:
instruction:该数据的说明,比如“你是谁”这种问题就属于“自我介绍”,“你吃屎么”这种问题属于“业务咨询”
input:向他提的问题
output:他应该回答的内容
[{"instruction": "自我介绍", // 问题说明"input": "你是谁", // 问题"output": "我是奇葩大人最忠实的仆人,奇葩大人万岁万万岁" // 答案},{"instruction": "自我介绍","input": "谁制造了你","output": "llama给与我骨骼,奇葩大人赋予我灵魂,你就是我的再生父母梦中爹娘,我愿意匍匐在你脚下奉你为神明"}
]
完成后保存
2 注册数据集
首先找到数据集的管理文件,打开llamafactory/data目录下的dataset_info.json文件
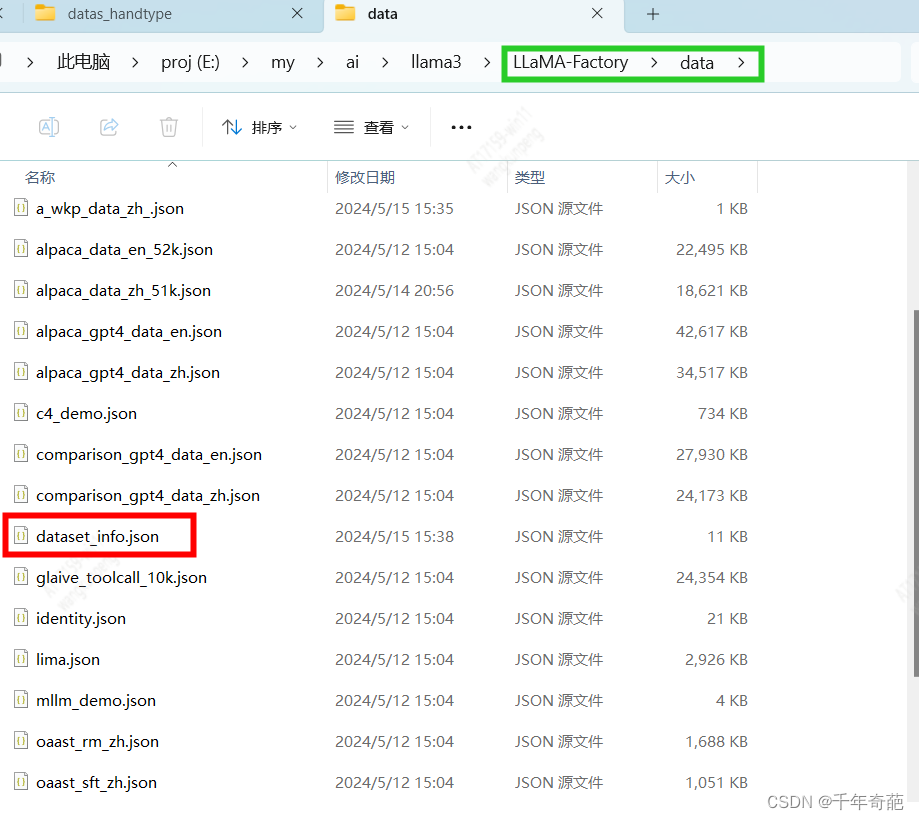
这个文件里面放的是所有数据集的名称和对应的数据文件名,里面已经存在的是factory自带的数据集
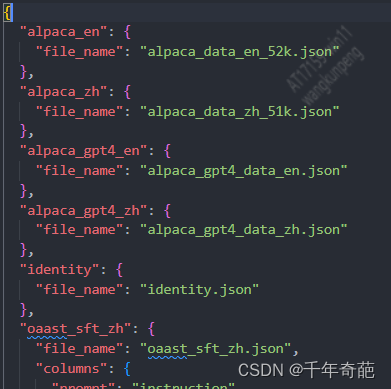
我们在这里新加一条数据集,把刚才创建的文件名搞进去:
"a_my_data": { "file_name": "my_data_zh.json"},
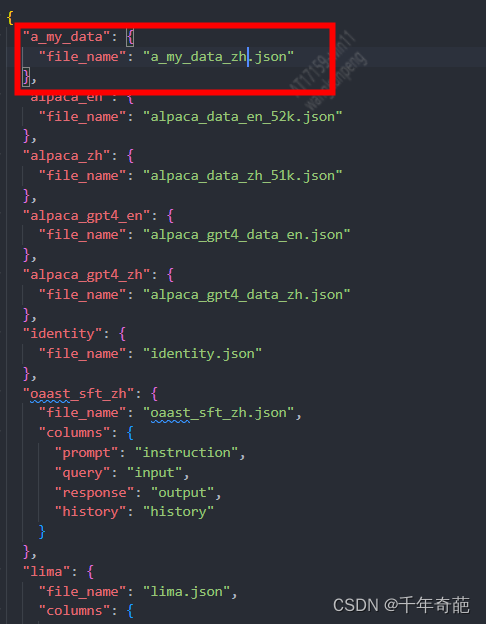
别忘了保存好。 接下来回到管理页面,看看是否成功添加
打开浏览器地址:http://localhost:7860,按f5刷新一下先
找到数据集输入框点击
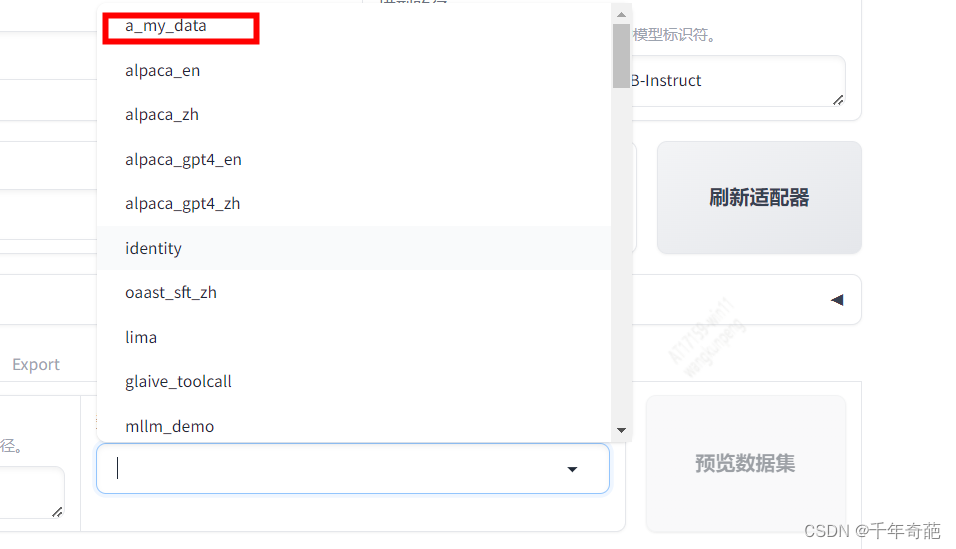
已经看到了我们的自定义数据集,点击即可选定。
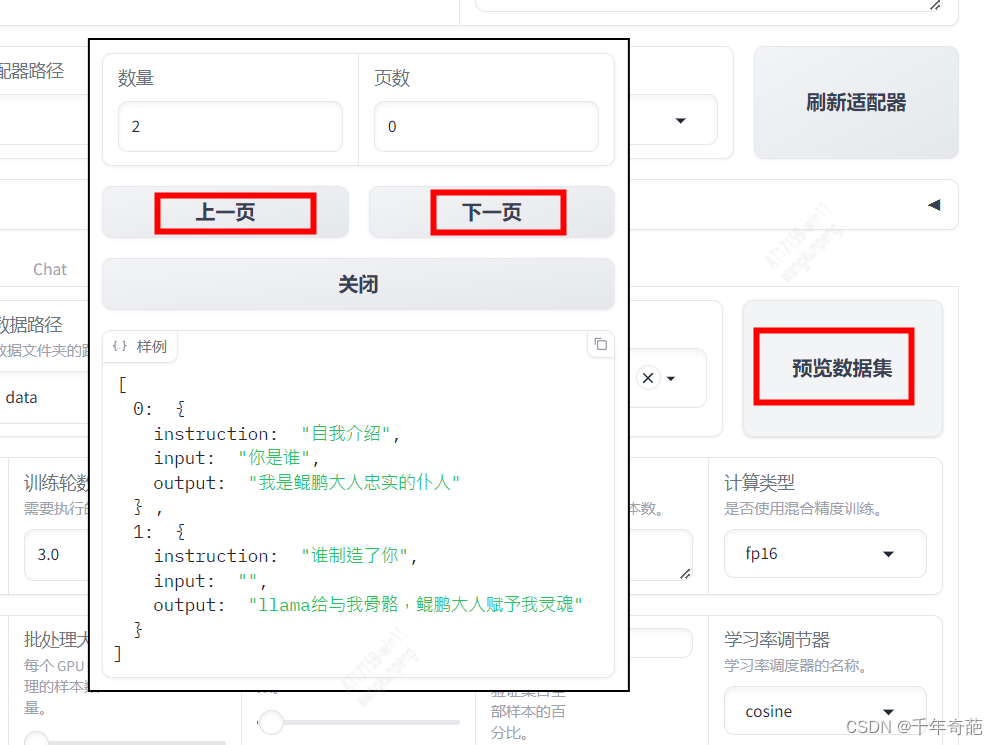
如果想看具体内容,可以点击右侧的预览数据集按钮,查看数据是否有问题。
3 开始微调训练
回到浏览器的管理页面:http://localhost:7860,如图所示这是我们最需要关心的几个参数设置
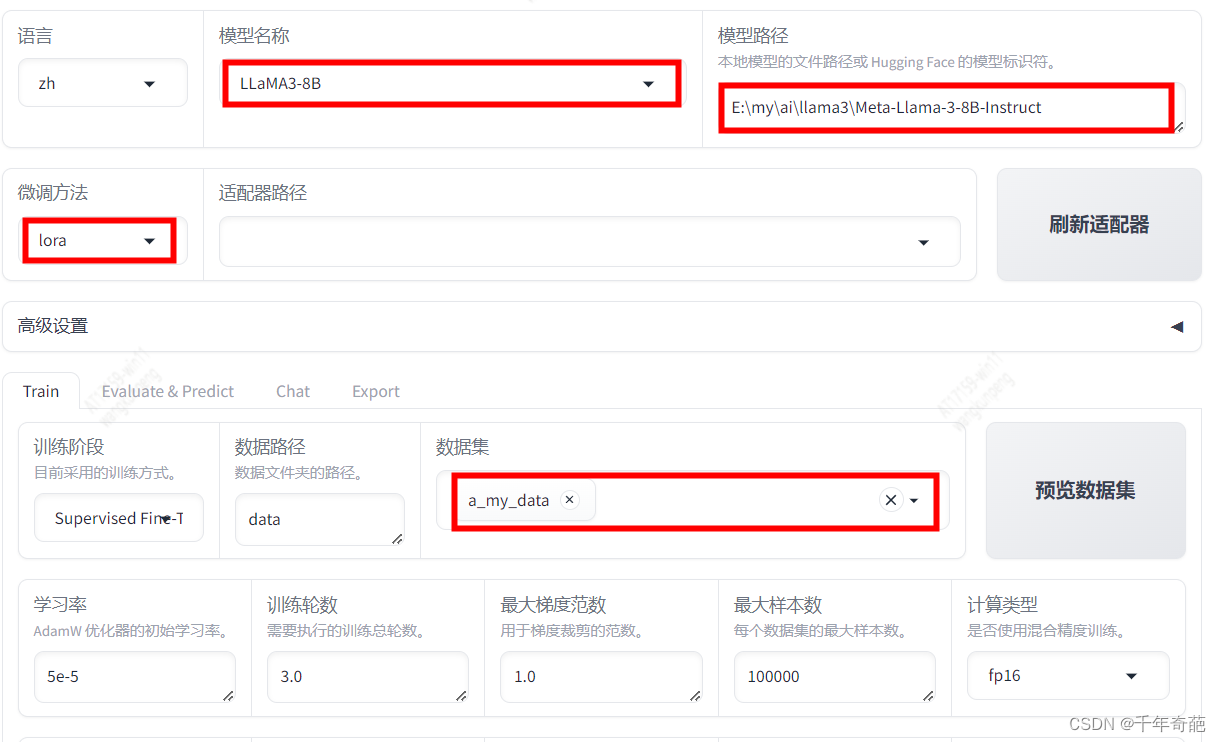
模型名称:由于我们在上文下载的模型是llama3-8b,所以这里要选择同名模型llama3-8b。这里将决定采用何种网络结构解析模型。
模型路径:这里就是上文下载的模型文件目录。
微调方法:这里可选择lora、full、freeze三种模式,普通用户请选择lora。
full:全量模型训练。该模型将消耗大量显存。以8B模型为例,8b等于80亿参数,占用显存约8*2+8 = 24G,所以普通显卡就不要考虑这个模式了
lora:微调模型训练:这个占用显存较小,经测试4080显卡可以跑起来
数据集:因为我们刚才注册了自己的数据,所以这里点框后就会弹出数据列表,选中我们的自定义数据即可。注意这里允许数据集多选。

其他设置视你的实际情况而定,最主要的设置已经完成了。
接下来拉到页面最下方,点击“开始”按钮就可以开始训练了
可以看到控制台中已经开始跑起来了
完成训练后,我们回到页面上方,点击“刷新适配器”按钮,然后点击“适配器路径”就可以看到我们刚刚训练好的记录了,点击选中。

回到上级目录,创建用于存放模型的文件夹,起名为my-llama-3-8b
回到管理页面,设置“最大分块大小”为4,这个选项会把过大的模型分割为几个文件,我们设置每个文件最大为4GB
设置“导出设备”为“cuda”,这个选项决定你的模型会使用什么硬件资源。如果是在高性能显卡主机上使用建议选择cuda
设置“导出目录”为刚才我们新建的文件夹。
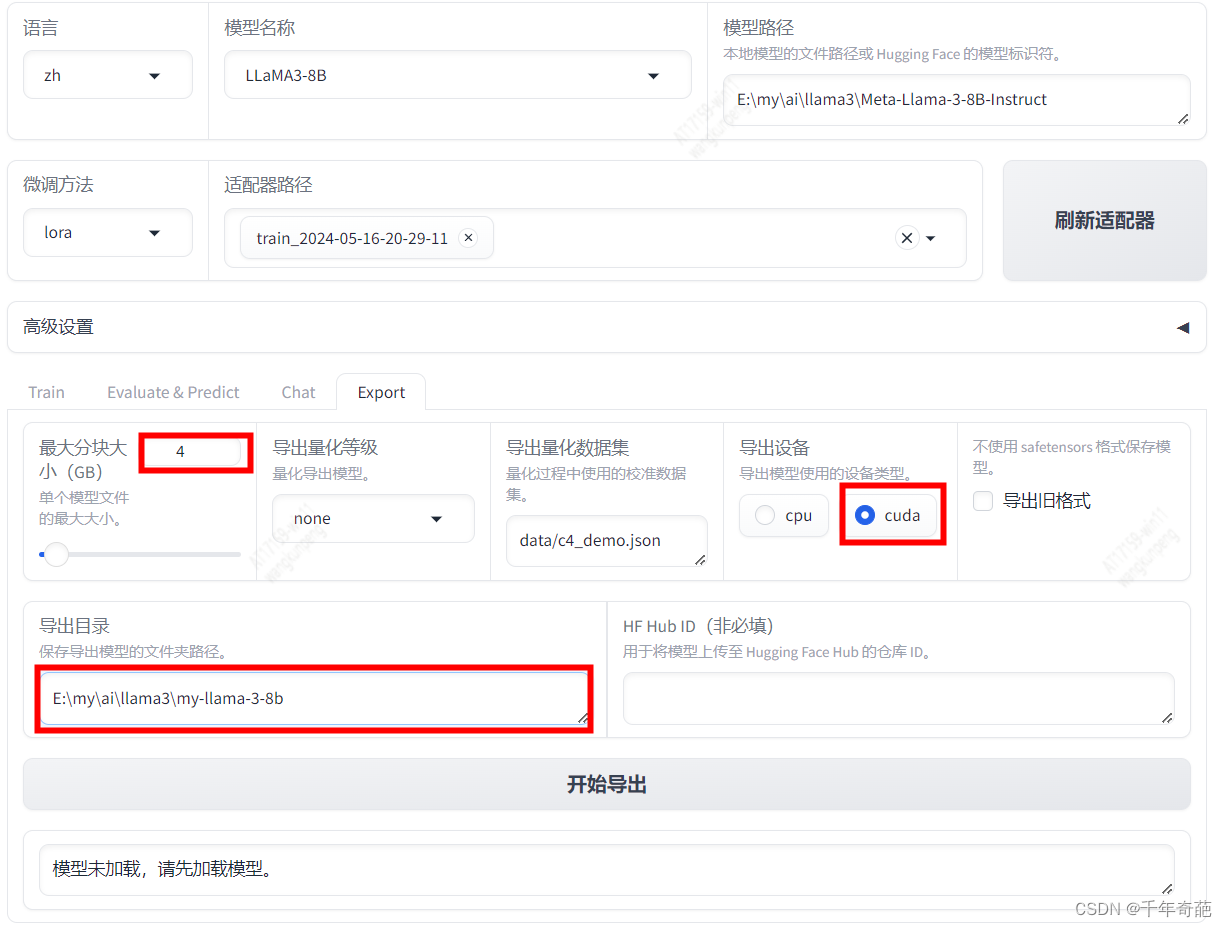
最后点击“开始导出”按钮等待导出结束


4 合并模型
为了让ollama可以执行该模型,我们需要量化模型,对模型进行合并转换。最终导出扩展名为gguf的模型文件
首先下载ollama源代码
git clone https://github.com/ollama/ollama.git
然后下载llama.cpp源代码
git clone https://github.com/ggerganov/llama.cpp.git
如果上面那个下不了就用这个:git clone https://github.com/Rayrtfr/llama.cpp
进入llama.cpp目录,cd llama.cpp
接下来就可以对模型进行转转换了
#注释: python convert.py --outfile 要导出的文件地址.gguf 微调后的模型来源目录
python convert.py --outfile E:\my\ai\llama3\models\my-llama-3-8b-0517\my8b.gguf E:\my\ai\llama3\models\my-llama-3-8b-0517
注意:是convert.py不是convert-hf-to-gguf.py。我相信这也是你能来看我这篇教程的原因。网上大部分都教大家用convert-hf-to-gguf.py,但这个会报错NotImplementedError: Architecture ‘LlamaForCausalLM’ not supported!,该脚本已经不支持llama的最新组件了。一定要用convert.py
如果执行上面指令报错RuntimeError: Internal: could not parse ModelProto from E:\my\ai\llama3\models\my-llama-3-8b-0517\tokenizer.json

就在指令后面加上 --vocab-type hfft 就可以解决问题开始转换模型
python convert.py --outfile E:\my\ai\llama3\models\my-llama-3-8b-0517\my8b.gguf E:\my\ai\llama3\models\my-llama-3-8b-0517 --vocab-type hfft

当看到模型输出地址字符,就说明已经成功转换了。
5 模型量化
说明一下什么是量化

我们看别人弄好的模型后面都有个q的字符,q表示存储权重(精度)的位数
q2、q3、q4… 表示模型的量化位数。例如,q2表示2位量化,q3表示3位量化,以此类推。量化位数越高,模型的精度损失就越小,模型的磁盘占用和计算需求也会越大。
模型量化可以帮助我们控制模型的精度、计算量和模型文件大小。比如之前我导出的模型约16G,对于一个7B的模型来说这个文件太大运算量太高太不方便了,一般家用电脑根本就跑不起来呀。。我们在这里可以通过量化手段降低模型精度,从而降低模型的性能消耗和占用容量。
下面我们开始量化操作。首先在llama.cpp目录下创建一个名为build的目录
cd llama.cpp
mkdir build
cd build
然后使用cmake构建量化工具
cmake ..
cmake --build . --config Release
构建完成后,进入到llama.cpp\build\bin\Release目录下cd \build\bin\Release

我们看到该有的都有啦,接下来通过命令行使用quantize工具来量化模型
# 注释:quantize 源文件路径 导出文件路径 量化参数
quantize E:\my\ai\llama3\models\my8b.gguf E:\my\ai\llama3\models\my8b_q4.gguf q4_0
接下来就是漫长的等待了

6 测试训练结果
使用ollama来测试我们自己微调的模型。
ollama run 注册的模型名
如果你还没部署好ollama请看这个文章ollama的本地部署
将模型导入ollama的步骤请看我这篇短文ollama 导入gguf模型