廊坊市 广阳区城市建设局网站全渠道营销
1 准备数据集
import torch
import torchvision
# 去网上下载CIFAR10数据集【此数据集为经典的图像数字识别数据集】
# train = True 代表取其中得训练数据集;
# transform 参数代表将图像转换为Tensor形式
# download 为True时会去网上下载数据集到指定路径【root】中,若本地已有此数据集则直接使用
train_data=torchvision.datasets.CIFAR10(root='./dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
# 测试数据集
test_data=torchvision.datasets.CIFAR10(root='./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 查看数据集长度
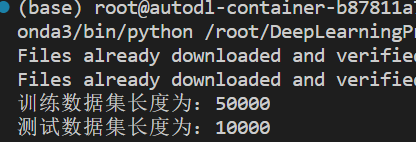
train_data_size=len(train_data)
test_data_size=len(test_data)
print('训练数据集长度为:{}'.format(train_data_size))
print('测试数据集长度为:{}'.format(test_data_size))
2 加载数据集
from torch.utils.data import DataLoader
# 将数据集加载,每64张作为一组
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
3 搭建神经网络
3.1 原理演示

Pytorch图像输入输出格式图像变换官方文档
此处仅举一个例子,即输入图像为3@32×323@32\times 323@32×32【3通道,高为32,宽为32】以通过5×55\times55×5卷积核进行卷积操作时需要填写哪些参数,使其变成32@32×3232@32\times 3232@32×32【32通道,高为32,宽为32】的图像
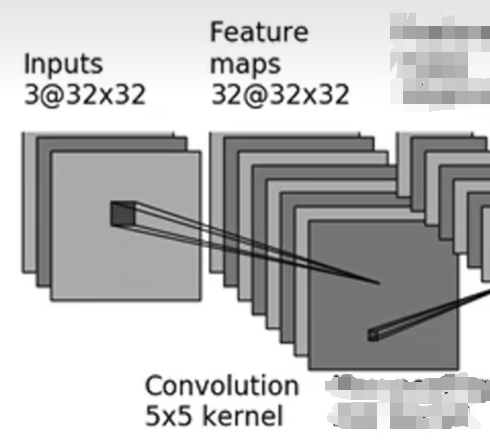
不知道卷积是啥意思的可以参考如下👇视频
B站土堆说卷积操作
官方文档中关于二维图像的卷积函数中的参数是这样解释的【此处仅对需要用到的部分进行注释】
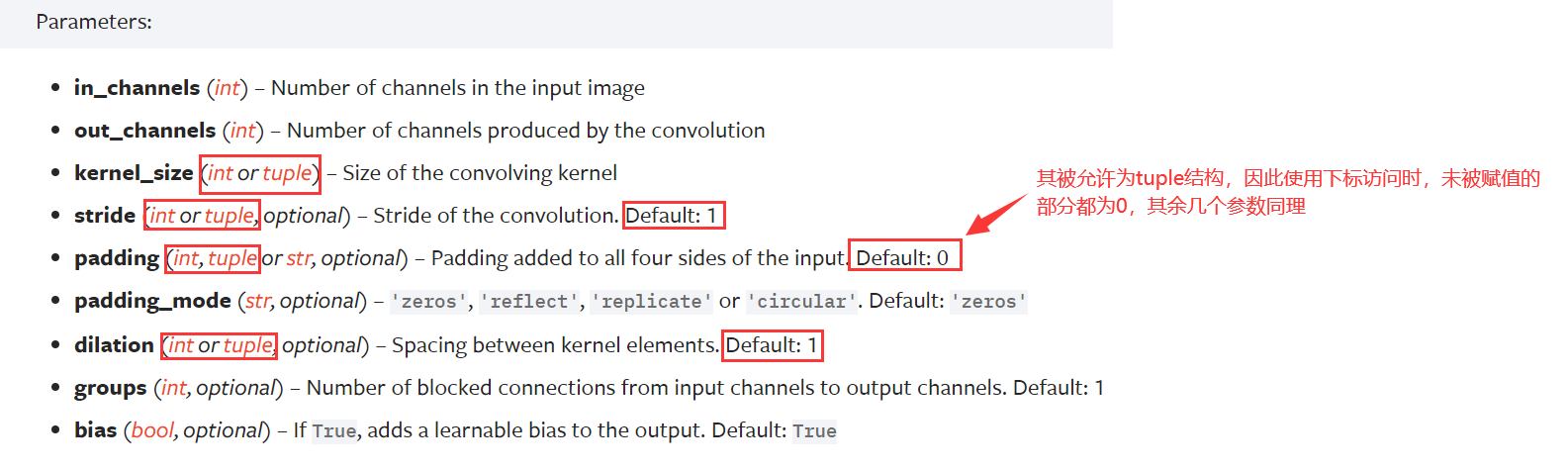
输入图像与输出图像的对应数学关系如下👇

图上没有采用空洞卷积,dilation参数默认是1,假设stride通常都是1,先尝试
Hout=⌊Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1stride[0]+1⌋32=⌊32+2×padding[0]−1×(5−1)−11+1⌋padding[0]=2Wout=⌊Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1stride[1]+1⌋∴同理可得,padding[1]也为2H_{out}=\left \lfloor \dfrac{H_{in}+2\times padding[0]-dilation[0]\times(kernel\_size[0]-1)-1}{stride[0]}+1 \right \rfloor \\ 32=\left \lfloor \dfrac{32+2\times padding[0] - 1\times (5-1)-1}{1}+1 \right \rfloor \\ padding[0]=2\\ \\ W_{out}=\left \lfloor \dfrac{W_{in}+2\times padding[1]-dilation[1]\times(kernel\_size[1]-1)-1}{stride[1]}+1 \right \rfloor \\ \therefore 同理可得,padding[1]也为2 Hout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋32=⌊132+2×padding[0]−1×(5−1)−1+1⌋padding[0]=2Wout=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋∴同理可得,padding[1]也为2
padding直接传入参数2即可,默认会将padding这个tuple都赋为2
# 因此进行如上变换需要传参如下
self.conv1 = Conv2d(in_channels=3, out_channels=32,kernel_size=5, stride=1, padding=2)
3.2 代码实现
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear
# 神经网络模型
class TrainModule(nn.Module):def __init__(self):super().__init__()# 按照上边参考图对数据依次进行如下处理,最后得到的就是关于当前图像的分类概率预测self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32,kernel_size=5, stride=1, padding=(2, 2)),# 最大池化操作nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),# 扁平化nn.Flatten(),# 线性处理nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xnet = TrainModule()
# 以下部分均为测试神经网络功能
# 模拟输入数据:64张图片。每个图的格式为3*32*32
input = torch.ones((64, 3, 32, 32))
# 调用神经网络类时会调用forward方法
output = net(input)
# 输出结果为torch.Size([64, 10]),说明返回结果是64张图片再十个数字类别中的概率
print(output.shape)
4 损失函数
我们通过比对预测值和真实值的差距从而得知模型的训练优劣,损失函数将这个指标数据化,损失函数越小,说明模型训练得越好
import tensorboard
from torch.utils.tensorboard import SummaryWriter
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器,SGD为随机梯度下降法
# 传入需要梯度下降的参数以及学习率,1e-2等价于0.01
optimizer = torch.optim.SGD(net.parameters(), lr=1e-2)# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练轮数【电脑性能有限,只打个样例】
epoch = 2
writer = SummaryWriter('./logs')
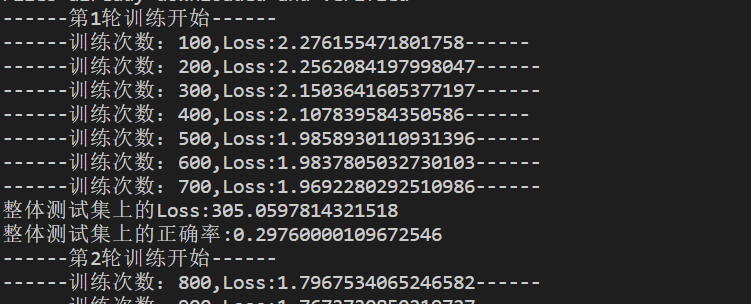
for i in range(epoch):print('------第{}轮训练开始------'.format(i+1))# 训练步骤开始for data in train_dataloader:imgs, targets = data# 将图片传入神经网络后得到输出结果outputs = net(imgs)# 将输出结果与原标签进行比对,计算损失函数loss = loss_fn(outputs, targets)# 在应用层面可以简单理解梯度清零,反向传播,优化器优化为三个固定步骤# 梯度清零optimizer.zero_grad()# 反向传播,更新权重loss.backward()# 对得到的参数进行优化optimizer.step()total_train_step += 1# 为避免打印太多,训练100次才打印1次if total_train_step % 100 == 0:# loss.item()作用是把tensor转为一个数字print('------训练次数:{},Loss:{}------'.format(total_train_step, loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)# 测试步骤开始total_test_loss = 0total_accuracy = 0# with的这段语句可以简单理解为提升运行效率with torch.no_grad():# 拿测试集中的数据来验证模型for data in test_dataloader:imgs, targets = dataoutputs = net(imgs)loss = loss_fn(outputs, targets)total_test_loss += loss.item()# agrmax(1)是将tensor对象按行看最大值下标进行存储,此处是数字图像,因此最大值下标实则就是我们的预测值# 此处是拿标签进行验证,统计预测正确的概率,方便后边计算正确率accuracy = (outputs.argmax(1) == targets).sum()total_accuracy += accuracyprint('整体测试集上的Loss:{}'.format(total_test_loss))print('整体测试集上的正确率:{}'.format(total_accuracy/test_data_size))writer.add_scalar('test_loss', total_test_loss, total_test_step)total_test_step += 1# 将每轮训练的模型都进行保存,方便以后直接调用训练完毕的模型torch.save(net, 'tarin_{}.pth'.format(total_test_step))writer.close()
5. 利用GPU训练【优化训练速度】
如何电脑有
GPU的话,优先 利用GPU进行训练速度会快很多
# 在有cuda方法的部分都加上
if torch.cuda.is_available():# 把数据交给GPU处理imgs = imgs.cuda()targets = targets.cuda()
如下方法也可以【常用】
# 指定device指向设备的第一张显卡
device = torch.device('cuda:0')
# 优先使用这张显卡处理
imgs = imgs.to(device)# 也可以这样指定防止出错
device = torch.device( "cuda" if torch.cuda.is_available() else "cpu")