信阳网站建设信阳怎么做外链
本文目标:
- 应用groupby 进行分组
- 对分组数据进行聚合,转换和过滤
- 应用自定义函数处理分组之后的数据
文章目录
- 1. 数据聚合
- 1.1 单变量分组聚合
- 1.2 Pandas内置聚合方法
- 1.3 聚合方法
- 使用Numpy的聚合方法
- 自定义方法
- 同时计算多种特征
- 向agg/aggregate传入字典
- 2. 数据转换
- 3. 数据过滤
1. 数据聚合
- 在SQL中我们经常使用 GROUP BY 将某个字段,按不同的取值进行分组, 在pandas中也有groupby函数
- 分组之后,每组都会有至少1条数据, 将这些数据进一步处理返回单个值的过程就是聚合,比如分组之后计算算术平均值, 或者分组之后计算频数,都属于聚合
1.1 单变量分组聚合
# 数据片段
'''country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
'''
df = pd.read_csv('data/gapminder.tsv', sep='\t')
# 单变量分组聚合
df.groupby('year').lifeExp.mean()'''
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
Name: lifeExp, dtype: float64
'''
1.2 Pandas内置聚合方法
-
可以与groupby一起使用的方法和函数
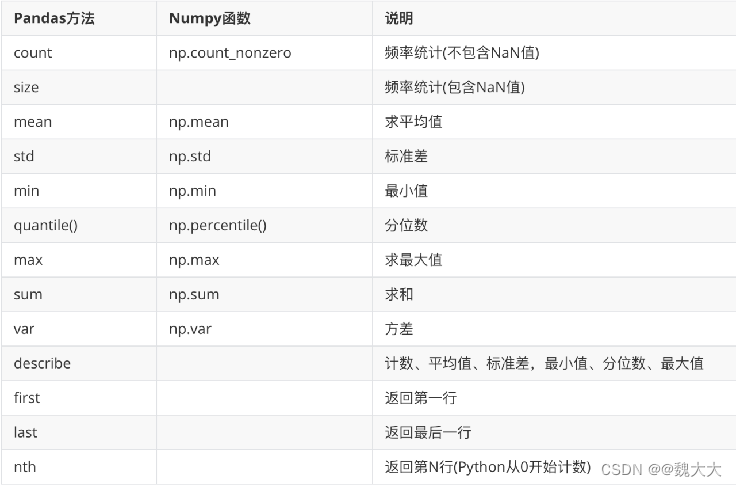
-
分组之后取平均也可以使用describe函数同时计算多个统计量
df.groupby('year').lifeExp.describe()
'''count mean std min 25% 50% 75% max
year
1952 142.0 49.057620 12.225956 28.801 39.05900 45.1355 59.76500 72.670
1957 142.0 51.507401 12.231286 30.332 41.24750 48.3605 63.03675 73.470
1962 142.0 53.609249 12.097245 31.997 43.46850 50.8810 65.23450 73.680
1967 142.0 55.678290 11.718858 34.020 46.03375 53.8250 67.41950 74.160
1972 142.0 57.647386 11.381953 35.400 48.50025 56.5300 69.24750 74.720
1977 142.0 59.570157 11.227229 31.220 50.47550 59.6720 70.38250 76.110
1982 142.0 61.533197 10.770618 38.445 52.94000 62.4415 70.92125 77.110
1987 142.0 63.212613 10.556285 39.906 54.94075 65.8340 71.87725 78.670
1992 142.0 64.160338 11.227380 23.599 56.12175 67.7030 72.58250 79.360
1997 142.0 65.014676 11.559439 36.087 55.63375 69.3940 74.16975 80.690
2002 142.0 65.694923 12.279823 39.193 55.52225 70.8255 75.45925 82.000
2007 142.0 67.007423 12.073021 39.613 57.16025 71.9355 76.41325 82.603
'''
1.3 聚合方法
使用Numpy的聚合方法
df.groupby('year').lifeExp.agg(np.mean)
# df.groupby('year').lifeExp.aggregate(np.mean)
'''
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
Name: lifeExp, dtype: float64
'''
agg()和aggregate()是一样的
自定义方法
计算每年的平均年纪:
def my_mean(values):n = len(values)sum = 0for v in values:sum += vreturn (sum / n)df.groupby('year').lifeExp.agg(my_mean)
多个参数的自定义方法:
def my_mean_diff(values,diff):n = len(values)sum = 0for v in values:sum+=vmean = sum/nreturn mean - diffdf.groupby('year').lifeExp.agg(my_mean_diff,diff=1)
同时计算多种特征
import numpy as np
df.groupby('year').lifeExp.agg([np.count_nonzero, np.mean, np.std])
'''count_nonzero mean std
year
1952 142 49.057620 12.225956
1957 142 51.507401 12.231286
1962 142 53.609249 12.097245
1967 142 55.678290 11.718858
1972 142 57.647386 11.381953
1977 142 59.570157 11.227229
1982 142 61.533197 10.770618
1987 142 63.212613 10.556285
1992 142 64.160338 11.227380
1997 142 65.014676 11.559439
2002 142 65.694923 12.279823
2007 142 67.007423 12.073021
'''
向agg/aggregate传入字典
分别对分组后的不同列使用不同聚合方法:
df.groupby('year').agg({'lifeExp': 'mean','pop': 'median','gdpPercap': 'median'}
)
'''lifeExp pop gdpPercap
year
1952 49.057620 3943953.0 1968.528344
1957 51.507401 4282942.0 2173.220291
1962 53.609249 4686039.5 2335.439533
1967 55.678290 5170175.5 2678.334740
1972 57.647386 5877996.5 3339.129407
1977 59.570157 6404036.5 3798.609244
1982 61.533197 7007320.0 4216.228428
1987 63.212613 7774861.5 4280.300366
1992 64.160338 8688686.5 4386.085502
1997 65.014676 9735063.5 4781.825478
2002 65.694923 10372918.5 5319.804524
2007 67.007423 10517531.0 6124.371108
'''
一步到位,把计算后的数据列进行命名:
df.groupby('year').agg({'lifeExp':'mean','pop':'median','gdpPercap':'median'
}).rename(columns={'lifeExp':'平均寿命','pop':'人口中位数','gdpPercap':'人均GDP中位数'
})'''平均寿命 人口中位数 人均GDP中位数
year
1952 49.057620 3943953.0 1968.528344
1957 51.507401 4282942.0 2173.220291
1962 53.609249 4686039.5 2335.439533
1967 55.678290 5170175.5 2678.334740
1972 57.647386 5877996.5 3339.129407
1977 59.570157 6404036.5 3798.609244
1982 61.533197 7007320.0 4216.228428
1987 63.212613 7774861.5 4280.300366
1992 64.160338 8688686.5 4386.085502
1997 65.014676 9735063.5 4781.825478
2002 65.694923 10372918.5 5319.804524
2007 67.007423 10517531.0 6124.371108
'''
2. 数据转换
- transform 需要把DataFrame中的值传递给一个函数, 而后由该函数"转换"数据。
- aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量
def zscore(x):return (x-x.mean())/x.std()
df.groupby('year').lifeExp.transform(zscore)
'''
0 -1.656854
1 -1.731249
2 -1.786543
3 -1.848157
4 -1.894173...
1699 -0.081621
1700 -0.336974
1701 -1.574962
1702 -2.093346
1703 -1.948180
Name: lifeExp, Length: 1704, dtype: float64
'''
使用Transform之后,产生的结果和原数据的数量是一样的。
使用Transform,可以对缺失值进行填充:
def fill_na_mean(bills):return bills.fillna(bills.mean())tips_10.groupby('sex')['total_bill'].transform(fill_na_mean)
3. 数据过滤
tips['size'].value_counts()
'''
2 156
3 38
4 37
5 5
1 4
6 4
Name: size, dtype: int64
'''
tips_filtered =tips.groupby('size').filter(lambda x:x['size'].count()>30)
tips_filtered['size'].value_counts()
'''
2 156
3 38
4 37
Name: size, dtype: int64
'''