国家城乡建设部信访网站seo谷歌

配置集群/分布式环境
1,修改文件workers
需要把所有节点数据节点的主机名写入该文件,每行一个,默认localhost(即把本机(namenode也作为数据节点),所以我们在伪分布式是没有配置该文件;
在进行分布式时需要删掉localhost(又可能文件中没有该配置,没有那就不用删了,配置一下数据节点

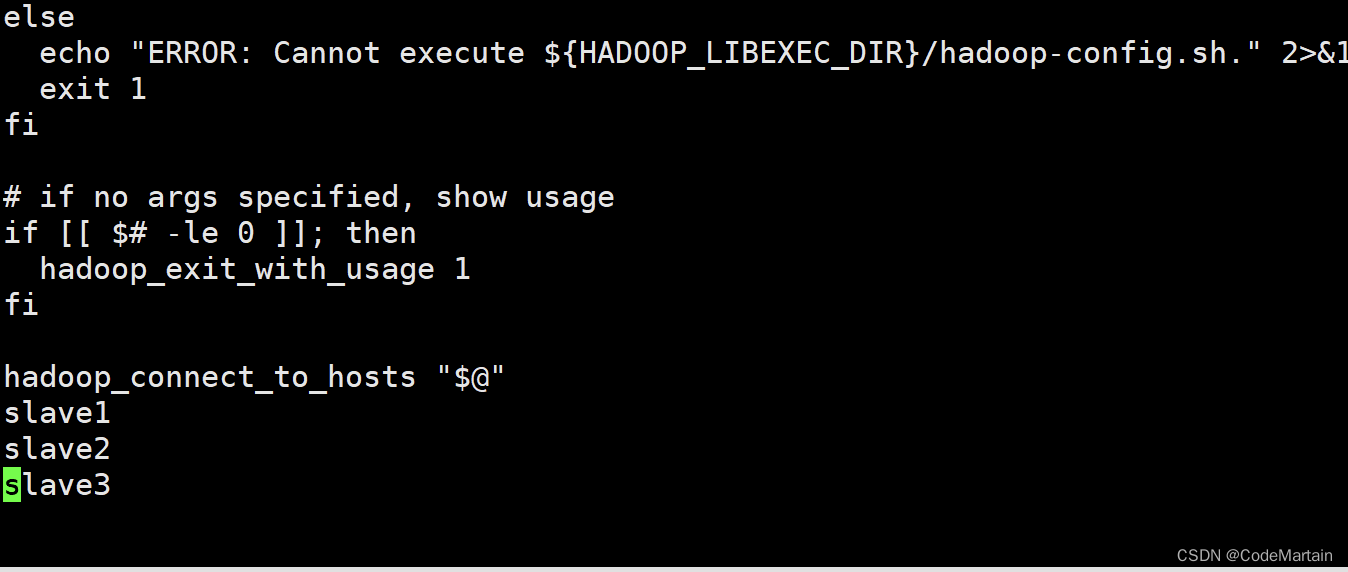
如果没有找到workers文件,请使用whereis 命令查找,呵呵
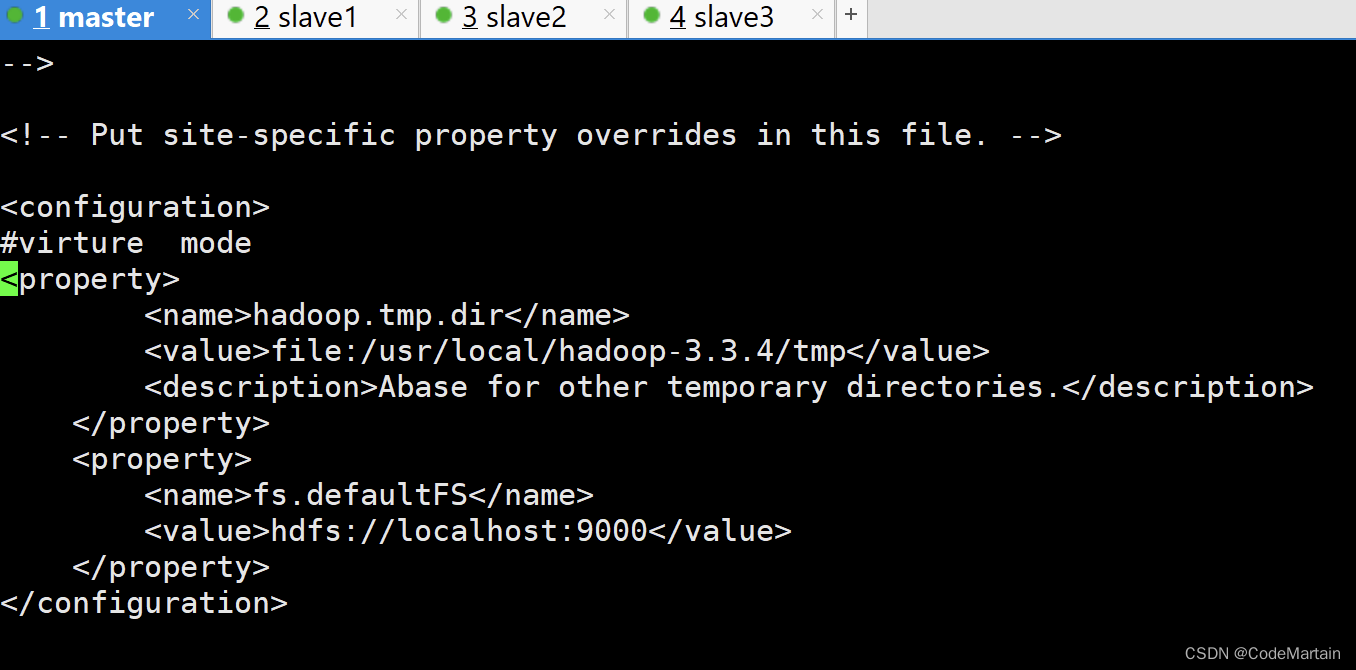
2,修改core-site.xml
vi /usr/local/hadoop-3.3.4/etc/hadoop/core-site.xml
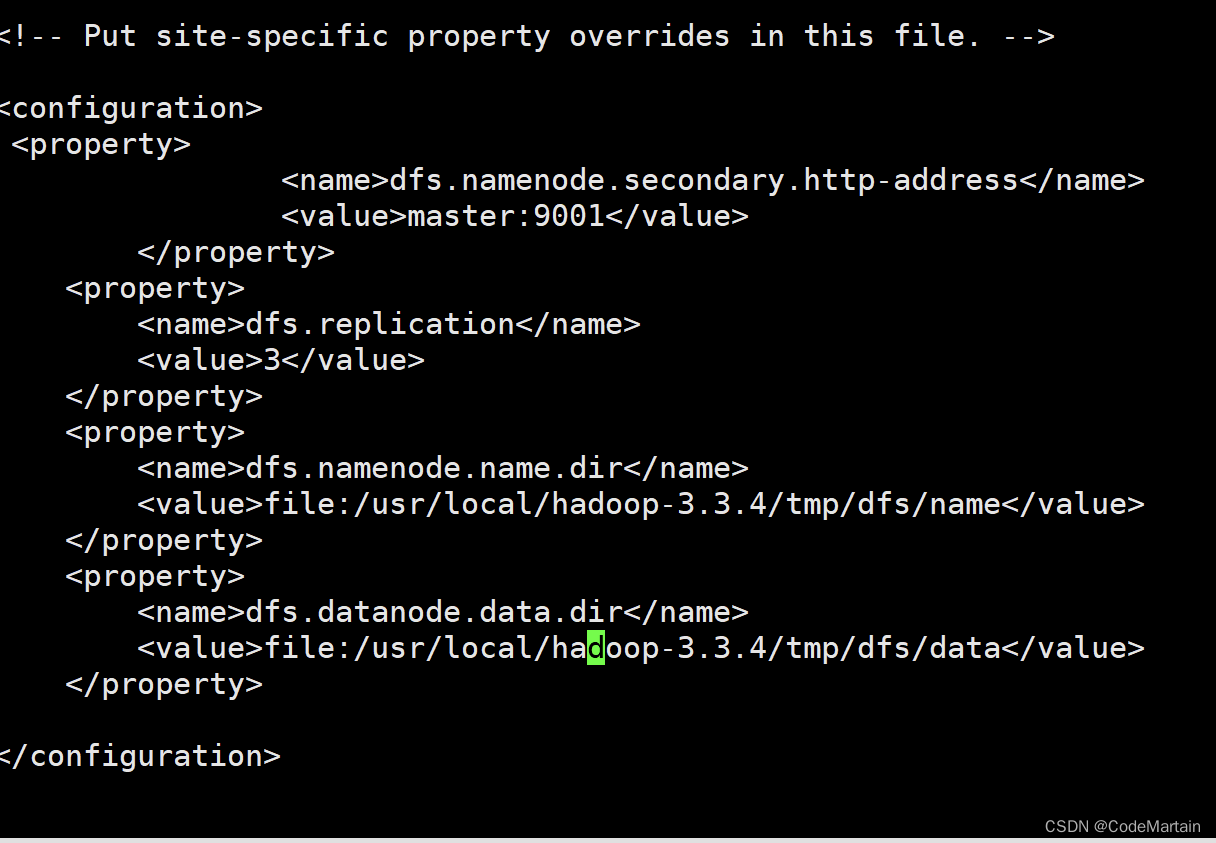
3,修改hdfs-site.xml文件
对于hadoop的分布式文件系统hdfs来讲,一般都是采用冗余存储的,冗余通常为3,也就是说,一份数据有三分副本,所以存1G的数据需要3G的容量;
4,修改marped-site.xml文件
将解压后的hadoop下的etc/hadoop/marped-site.xml 修改;

5,修改yarn-site.xml文件
在mapred-site.xml同文件夹下修改yarn-site.xml文件
修改后的文件内容如下

配置完毕之后,需要将master节点上的hadoop-3.3.4文件夹复制到各个节点之上;
注意:在这里要先删除之前运行hadoop生成的临时文件;
[root@master hadoop-3.3.4]# rm -rf tmp/
[root@master hadoop-3.3.4]# rm -rf logs/
[root@master hadoop-3.3.4]# cd ../
[root@master local]#rm -rf hadoophadoop-3.3.4.tar.gz将文件压缩,方便传输
tar -zcf hadoop-3.3.4.tar.gz ./
压缩时间还是挺长的
 将slave*节点上的临时文件也给删除掉
将slave*节点上的临时文件也给删除掉
[hadoop@slave3 .ssh]$ su root
Password:
[root@slave3 .ssh]# cd /usr/local/hadoop-3.3.4/
[root@slave3 hadoop-3.3.4]# rm -rf tmp
[root@slave3 hadoop-3.3.4]# rm -rf logs
[root@slave3 hadoop-3.3.4]# cd ../
[root@slave3 local]# rm -rf hadoop-3.3.4.tar.gz
#这里hadoop-3.3.4文件夹也要删除,因为要用master节点配置好的
[root@slave3 local]# rm -rf hadoop-3.3.4.tar.gz
[root@slave3 local]# rm -rf hadoop-3.3.4
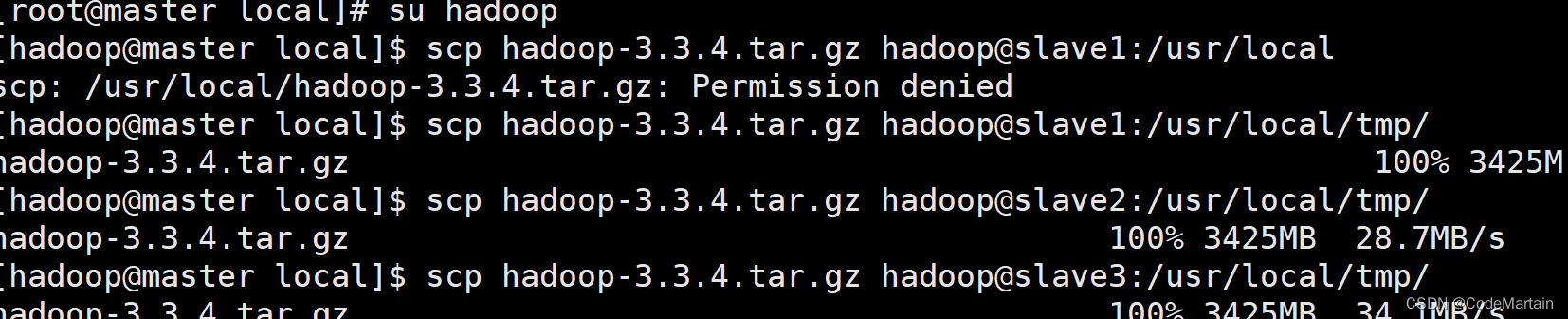
[root@slave3 local]# ls从master节点传输hadoop的压缩文件传输到各个节点上
[hadoop@master local]$ scp hadoop-3.3.4.tar.gz hadoop@slave1:/usr/local
scp: /usr/local/hadoop-3.3.4.tar.gz: Permission denied
被拒绝了…
我的猜测是文件的权限不够,
于是修改文件所属为hadoop,授予文件700权限,还是不可以;
这说名不是源端文件问题,只能是目标端权限问题;
/usr/local文件权限不能随便改,于是我在local下建了一个 临时文件夹,传输完成后,将文件夹移来;

master节点执行scp操作:

操作成功,其他节点也一样操作即可~略
下面在master节点上初始化namenode和datenode节点所需要的文件夹
hdfs namenode -format
注意:首次启动hadoop时需要格式化namenode和datanode
hadoop的启动
启动hdfs 系统
start-dfs.sh
正常启动如下:

启动yarn~管理工具
start-yarn.sh
启动了资源节点管理以及节点管理

启动守护进程
[hadoop@master hadoop]$ mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
此处提示该命令被废弃了(这个跟hadoop版本有关,按照提示,使用mapred --daemon start 代替上述命令
[hadoop@master sbin]$ mapred --daemon start historyserver
[hadoop@master sbin]$
查看启动的进程:
jps

过一会守护进程就退出了
另一个我们看一下最新的mapred --daemon 的命令:
该命令后只能跟start stop status

浏览器输入master节点IP:配置的端口号
本次配置的地址如下:
http://192.168.8.135:9001/
页面展示如下

执行分布式实例
创建HDFS分布式文件系统的用户目录
执行如下命令:
hdfs dfs -mkdir -p /usr/hadoopHDFS中创建一个input目录,并把 hadoop配置文件复制到input目录中(整个过程就如之前伪分布式操作的一样)
还是不一样的,首先得学习一下hdfs系统的命令
之前不是建立一个 /usr/hadoop文件夹了吗,
 明白这点之后,再去执行hadoop命令
明白这点之后,再去执行hadoop命令
额发生了点小故障,待我瞧瞧如何解决;

2023-03-08 05:29:42,288 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.8.135:8032
2023-03-08 05:29:43,986 INFO ipc.Client: Retrying connect to server: master/192.168.8.135:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
说是链接8032端口超时,我们看一下哪里配置了8032端口(也许是该端口没有开放的缘故吧)
未完待续