网站购买后如何做任何东西都能搜出来的软件
一、仅用pd加载大文件(iterator、chunksize)
要使用Pandas进行高效加载超大文件,我们通常会利用其内置的分块(chunk)处理功能。不过,请注意,Pandas本身并不支持多线程读取文件;它更倾向于单线程中进行块处理。尽管如此,对于优化加载超大文本文件这一场景,可以通过以下方式实现提速:
- 预先知道或估计每个数据块的行数或大小。
- 利用
pandas.read_csv等方法的chunksize参数来迭代读取数据。- 使用多进程而非多线程来并行处理每一块数据(如果确实需要并发执行),因为Python中GIL(全局解释器锁)限制了同一时刻只能有一个线程执行Python字节码。
下面是一个示例代码。请注意,在此示例中没有直接采用多进程来读取文件分片。相反,我们首先以流式模式逐步载入小数据块,并在必要时可应用某种形式的并行处理框架(如Dask)针对这些已经被逐步载入内存中DataFrame对象进行后续操作。
import pandas as pd
class EfficientTextLoader:"""采用pandas高效加载超大文本文件"""def __init__(self, filepath, chunksize=10000):"""初始化:param filepath: 文件路径:param chunksize: 每次迭代加载的行数,默认设定为10000条记录/行注意:根据你系统和硬件配置调整chunksize大小以获得最佳性能。较小值减少内存消耗但增加I/O频率;较大值则反之。"""self.filepath = filepath# Pandas 从版本0.24 开始支持 TextFileReader 属性 'chunksize'.# 当使用 read_csv 等函数与 'iterator=True' 结合时,# 设置 'chunksize' 可返回 TextFileReader 对象供迭代.self.chunk_size = chunksizedef load(self):"""按照指定chunks逐渐地、有效地装载整个文档"""reader = pd.read_csv(self.filepath,sep='\t', # 假设是制表符分隔的TXT 文档;根据需求而定 iterator=True,header=None,chunksize=self.chunk_size) # 逐行加载chunks = []try:while True:chunks.append(next(reader)) ## 这里可以添加额外代码对当前Chunk进行预处理或转换 ##except StopIteration: print("Iteration is stopped.")data_concatenated=pd.concat(chunks,axis=0) return data_concatenated上述代码做出了几点修改与优化:
1. 使用
pd.read_csv()的iterator=True和chunkSize=参数创建一个可循环遍历所有区段(chunk) 的阅读器 (reader),从而允许手动控制流水线(pipeline) 中各部分内容何时被具体导入到RAM之中。2. 利用 Python 的异常控制结构完成对全部区段(chunk) 数据依次导入直至结束——当无更多内容可供导出(
StopIteration)时跳出循环,并将所有已经在列表(chunks) 中累积起来单元结果合成(concatenate)为最终 DataFrame 对象给予输出。备注: 而关于真正意义上“利用Panda和* 多线性 *” —— 实际情况复杂许多且易受 Python GIL 影响;通常建议替代方案比如 Dask 来达成类似需求。
普通的pandas加载多个文件,pandas加载文件不支持通配符,因此需要glob包来辅助
import pandas as pd import glob # 获取所有匹配路径下CSV格式文档列表 files = glob.glob('path/to/your/files/data_*.csv') # 循环遍历每个文档, 读取后添加至列表中 dfs = [pd.read_csv(file) for file in files] # 将这些 DataFrame 合并成一个 DataFrame (注意: 确保各DataFrame结构相同) df_combined = pd.concat(dfs)pandas 在加载3个2G大小文件时,耗时约为 80s
二、Dask + pd 加载处理大文件
使用Dask优化原有基于Pandas的代码以提高处理超大文件的能力是一个很好的选择。Dask是Python中一个流行且强大的并行计算库,它可以无缝扩展Numpy、Pandas等数据处理操作到分布式计算环境中。
下面展示如何用Dask重新实现之前讨论过加载超大文本文件功能:
import dask.dataframe as ddclass DaskTextLoader:def __init__(self, filepath, blocksize=1024 * 1024 * 128): # 默认块大小为128MB"""使用 Dask 初始化加载器。:param filepath: 要读取的文件路径。:param blocksize: 单个块(block)读入内存时占用字节大小,默认值设定为128MB。根据你系统和硬件配置调整blocksize大小以获得最佳性能,较小值将导致更多、但管理起来较易控制(内存使用上)单元任务;较大则减少任务数量但每个任务更耗时及可能引发更高内存消耗压力。注意:该参数仅针对文本数据有效,如CSV或JSON格式。如果输入其他格式(比如Parquet)DASK将自动管理最佳块划分策略而忽略此设置项。"""self.filepath = filepathself.blocksize = blocksizedef load(self):# 加载txt/csv/json... 文件并返回dask DataFrame对象.df = dd.read_csv(self.filepath, blocksize=self.blocksize)## 这里可以添加任何必要预处理步骤 ##return df这段代码通过
dd.read_csv()函数来读取文本类型数据,并允许通过blocksize参数来控制加载到内存中每个块(chunk) 的大小。这对于处理非常庞大的文件特别有用因为它允许在不完全加载整个文件到RAM情况下进行分片并行操作。一旦得到了Dask DataFrame 对象 (
df) 后即可利用类似 Pandas 的API进行各种复杂操作与运算—例如过滤(filtering), 分组(grouping), 汇总(aggregating), 转换(transformations)—只需记住结果通常也呈现异步形态;故而在需要具体结果前须调用.compute()方法触发真正执行所有累积待办事务序列链条:result_df = df.compute() # 触发实际执行获取Pandas DataFrame结果对象result_df = df.head(5) # 触发实际执行获取Pandas DataFrame结果对象,只获取5条请注意,尽管
.compute()返回标准 Pandas DataFrame 对象包括其所含全部数据项——针对极端庞大规模集合可能会再度碰撞 内存在限制问题; 因此,在设计解决方案结构时应当谨慎试图一次性完全求解而考虑是否逐部递进或者仍然保持部分工作流程在 DASK 执行框架上面智能地选段完成具体细则需求点。
三、自定义单机/多机多线程 dask + pd 加载预处理大文件
要在单机环境中对Dask进行多进程数的控制,你可以使用
dask.distributed模块创建一个本地集群,并控制其工作进程数量。通过这种方式,你能够显式地设定并发执行任务的工作线程或进程数目。以下是如何修改上述代码来加入单机多进程控制的示例:
from dask.distributed import Client, LocalCluster
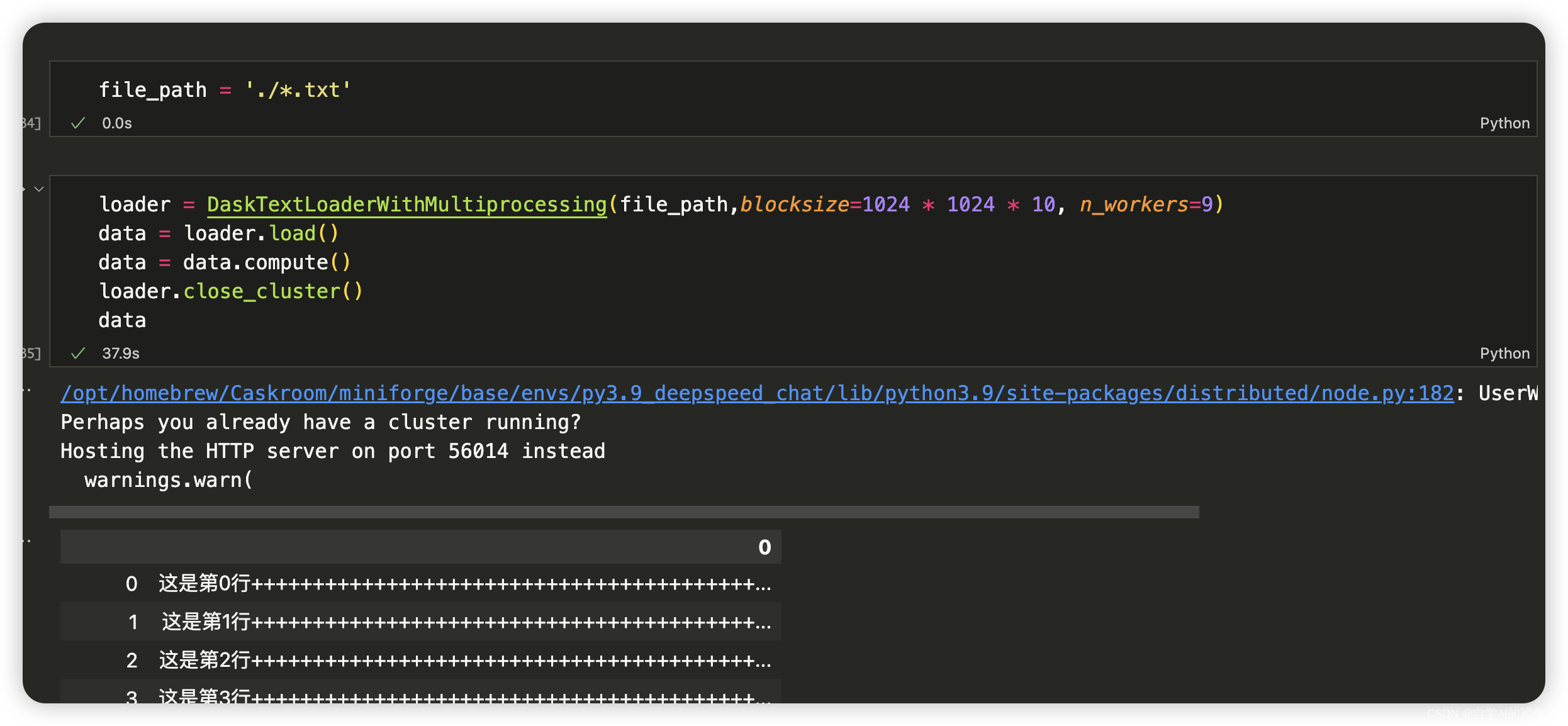
import dask.dataframe as ddclass DaskTextLoaderWithMultiprocessing:def __init__(self, filepath, blocksize=1024 * 1024 * 128, n_workers=4):"""使用 Dask 初始化加载器并设置多处理。:param filepath: 要读取的文件路径。:param blocksize: 单个块(block)读入内存时占用字节大小,默认值设定为128MB。根据系统和硬件配置调整blocksize大小以获得最佳性能,较小值将导致更高I/O频率但容易管理(内存使用上);较大则减少任务数量但每个任务更耗时及可能引发更高内存消耗压力。注意:该参数仅针对文本数据有效,如CSV或JSON格式。如果输入其他格式(比如Parquet)DASK将自动管理最佳块划分策略而忽略此设置项。:param n_workers: 并行工作线程/进程数,默认为4.增加此数字可并行执行更多操作,但也会增加系统资源消耗。"""self.filepath = filepathself.blocksize = blocksize# 创建本地DASK集群 cluster = LocalCluster(n_workers=n_workers)self.client = Client(cluster)def load(self):# 加载txt/csv/json... 文件并返回dask DataFrame对象.df = dd.read_csv(self.filepath, header=None, # 是否使用头sep='\t', # csv 分隔符blocksize=self.blocksize)## 这里可以添加任何必要预处理步骤 ##return df def close_cluster(self):# 关闭client和cluster self.client.close()在这段代码中,我们首先创建了一个
LocalCluster实例,并通过参数n_workers=n_worksers,指明了我们想要在集群中启用的工作者(Worker)数量即实际运行计算操作所使用到核心/线程序列总量。紧接着利用该cluster构造出 aClient, 其扮演着用户与集群之间交互接口角色方便提交相关计算任务请求等功能使命完结后续各类数据操作需求点。请注意,在完成所有需要做的计算之后调用
.close()方法关闭客户端(Clients)与服务端(Cluster),释放相关资源非常重要;特别情况下如果忘记手动关闭可能会导致程序未正常结束情形下挂起保持运行状态占据宝贵资源直至外部干预才得以解决问题。
举个完整的例子来执行该代码
首先,假设已经有了一个CSV文件
example.csv,该文件内容大致如下:
name,age,city
Alice,34,Berlin
Bob,23,London
Charlie,45,New York
现在目标是使用上面定义的Dask处理类来读取这个CSV文件,并计算年龄列(
age)的平均值。
代码示例如下:
# 使用定义好的加载器来读取数据,然后多线程处理数据。
loader = DaskTextLoaderWithMultiprocessing('example.csv', n_workers=2) ## 假设您希望用2个工作进程运行df_dask = loader.load() ## 调用load方法得到dask DataFrame对象 average_age_computed_future=df_dask.age.mean() ## 计算年龄平均值操作 (延迟执行) average_age_result=average_age_computed_future.compute() ### 触发实际执行并获取结果(阻塞直到完成)
print(f"The average age is: {average_age_result}")loader.close_cluster() ### 记住关闭集群释放资源!以上代码段展示了从头至尾创建一个可以控制单机多进程数 的
DASK Text Loader, 然后利用它去异步地读取一个CSV格式文本数据、计算某特定数值列(此处为“age”年龄字段)内所有元素平均值,并最终输出该统计结果。
使用 dask 加载多个文件
使用 Dask 加载多个文件假设你有一系列以相同模式命名(例如data_*.csv)的CSV文件想要加载:import dask.dataframe as dd# 用通配符 '*' 加载匹配到的所有 CSV 文件 df = dd.read_csv('path/to/your/files/data_*.csv')
下面是dask + pd 加载3个2g的文件,耗时约37s,n_workers指定越多,文件大小和文件数量越大,差距拉的就越大